
Objetivos de la lección
Esta lección explica por qué numerosas instituciones culturales están adoptando bases de datos orientadas a grafos (graph databases) y cómo los investigadores pueden acceder a estos datos a través de consultas realizadas en el lenguaje llamado SPARQL.
Contenidos
- Objetivos de la lección
- Bases de datos orientadas a grafo, RDF y datos abiertos enlazados (Linked Open Data, LOD)
- Consultas basadas en casos reales
- Trabajando con resultados SPARQL
- Lecturas adicionales
Bases de datos orientadas a grafo, RDF y datos abiertos enlazados (Linked Open Data, LOD)
Actualmente, numerosas instituciones culturales están ofreciendo información sobre sus colecciones a través de las denominadas API (Application Programming Interfaces). Estas API son instrumentos muy eficaces para acceder de manera automatizada a registros individuales, sin embargo, no constituyen el procedimiento ideal cuando tratamos con datos culturales debido a que las API están estructuradas para trabajar con un conjunto predeterminado de consultas (queries). Por ejemplo, un museo puede tener información sobre donantes, artistas, obras de arte, exposiciones, procedencia de sus obras (provenance), etc., pero su API puede ofrecer solo una recuperación orientada a objetos, haciendo difícil o imposible buscar datos relacionados con donantes, artistas, etc. Así pues, esta estructura es interesante si el objetivo es buscar información sobre objetos particulares; sin embargo, puede complicar la operación de agregar información sobre los artistas o donantes que también se encuentran registrados en la base de datos.
Las bases de datos RDF son muy apropiadas para expresar relaciones complejas entre múltiples entidades, como personas, lugares, eventos y conceptos ligados a objetos individuales. Estas bases de datos se denominan habitualmente bases de datos orientadas a grafos (graph databases) porque estructuran la información como un grafo o red, donde un conjunto de recursos o nodos están conectados entre sí mediante aristas (o enlaces) que describen las relaciones establecidas entre dichos recursos y/o nodos.
Dado que las bases de datos RDF admiten el uso de URL, estas pueden estar accesibles online y también pueden enlazarse a otras bases de datos, de ahí el término “datos abiertos enlazados” (Linked Open Data, LOD). Importantes colecciones artísticas, entre las que se incluyen las del British Museum, Europeana, el Smithsonian American Art Museum y el Yale Center for British Art, han publicado sus colecciones de datos como LOD. El Getty Vocabulary Program también ha publicado sus vocabularios controlados (TGN, ULAN y AAT) como LOD.
SPARQL es el lenguaje utilizado para interrogar este tipo de bases de datos. Este lenguaje es particularmente potente porque obvia las perspectivas que los usuarios transfieren a los datos. Una consulta sobre objetos y una consulta sobre donantes son prácticamente equivalentes en estas bases de datos. Lamentablemente, numerosos tutoriales sobre SPARQL utilizan modelos de datos tan extremadamente simplificados que no son operativos cuando se trata de utilizar las complejas bases de datos desarrolladas por las instituciones culturales. Este tutorial ofrece un curso intensivo sobre SPARQL utilizando un conjunto de datos (dataset) que un humanista podría realmente encontrar en Internet. En concreto, en este tutorial aprenderemos cómo interrogar la colección LOD del British Museum.
RDF en pocas palabras
RDF representa la información en una declaración triple -también llamada tripleta- que sigue la estructura sujeto-predicado-objeto. Por ejemplo:
<La ronda de noche> <fue creada por> <Rembrandt van Rijn> .
(Observa que, como toda buena oración, estas declaraciones terminan con un punto y final).
En este ejemplo, el sujeto <La ronda de noche> y el objeto <Rembrandt van Rijn> pueden ser considerados como dos nodos de un grafo, donde el predicado <fue creada por> define la arista -o relación- entre ellos. (Técnicamente,
Una seudobase de datos RDF podría contener declaraciones interrelacionadas entre sí, como las siguientes:
...
<La ronda de noche> <fue creada por> <Rembrandt van Rijn>.
<La ronda de noche> <fue creada en> <1642>.
<La ronda de noche> <utiliza la técnica de> <óleo sobre lienzo>.
<Rembrandt van Rijn> <nació en> <1606>.
<Rembrandt van Rijn> <es de nacionalidad> <holandesa>.
<Johannes Vermeer> <es de nacionalidad> <holandesa>.
<La tasadora de perlas> <fue creada por> <Johannes Vermeer>.
<La tasadora de peras> <utiliza la técnica de> <óleo sobre lienzo>.
...
Si visualizásemos estas declaraciones como nodos y aristas de un grafo o red, la representación sería como sigue:
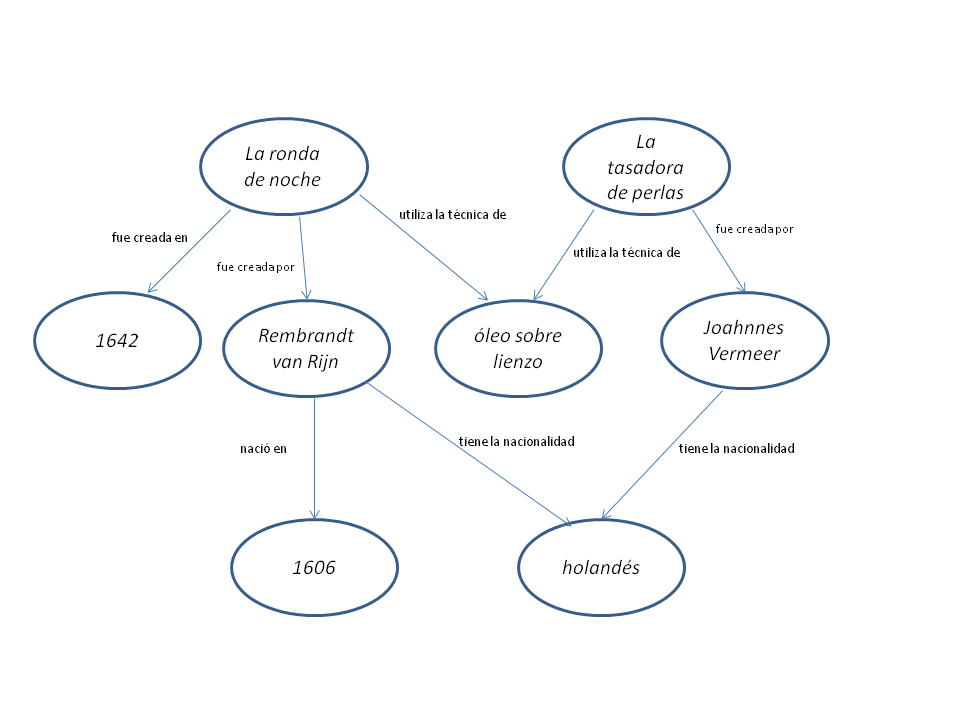
Visualización en red del seudoRDF mostrado más arriba. Las flechas indican la ‘dirección’ del predicado. Por ejemplo, que ‘La tasadora de perlas fue creada por Vermeer’ y no al revés. Diagrama reconstruido por Nuria Rodríguez Ortega.
Las tradicionales bases de datos relacionales pueden distribuir atributos sobre obras de arte y artistas en tablas separadas. En las bases de datos RDF u orientadas a grafos, todos estos datos pertenencen a un mismo mismo grafo interconectado, lo que permite a los usuarios una mayor flexibilidad a la hora de decidir cómo quieren interrogar estos recursos.
Buscando RDF con SPARQL
SPARQL nos permite traducir datos en grafo, intensamente enlazados, en datos normalizados en formato tabular, esto es, distribuidos en filas y columnas, que se pueden abrir en programas como Excel o importar a programas de visualización, tales como plot.ly o Palladio.
Resulta útil pensar las consultas SPARQL como un Mad Lib -un conjunto de oraciones con espacios en blanco-. La base de datos tomará esta consulta y encontrará cada conjunto de oraciones que encaje correctamente en estos espacios en blanco, devolviéndonos los valores coincidentes como una tabla. Veamos esta consulta SPARQL:
SELECT ?pintura
WHERE {
?pintura <utiliza la técnica de> <óleo sobre lienzo> .
}
En este consulta, ?pintura representa el nodo (o nodos) que la bases de datos nos devolverá. Una vez recibida la consulta, la base de datos buscará todos los valores para ?pintura que adecuadamente complete la declaración RDF <utiliza la técnica de> <óleo sobre lienzo>.
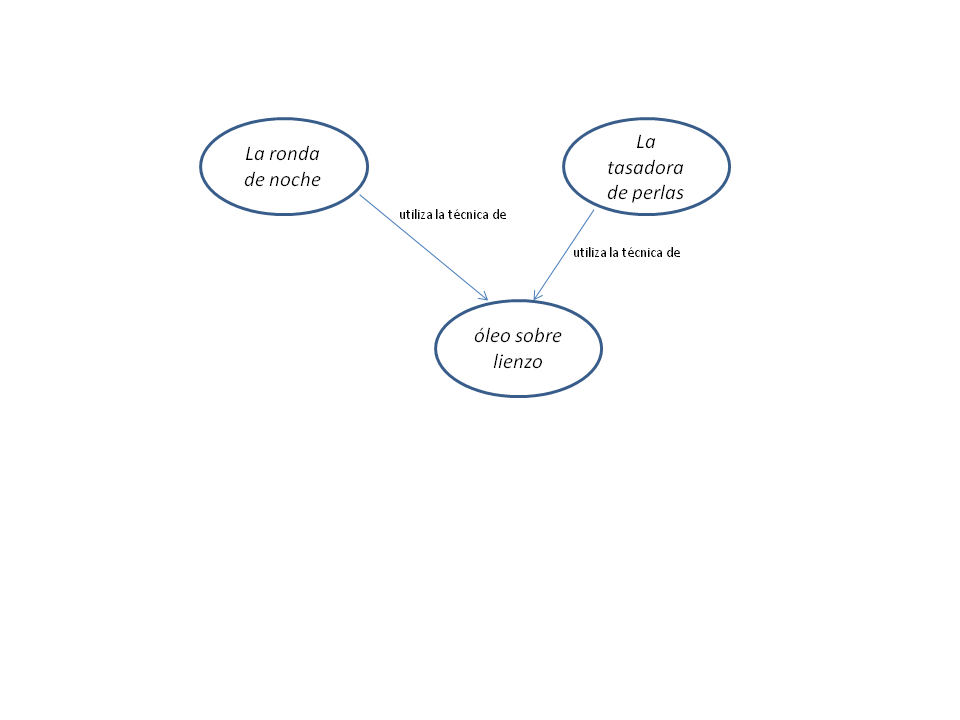
Visualización de lo que nuestra consulta está buscando. Diagrama reconstruido por Nuria Rodríguez Ortega.
Cuando la consulta interroga la base de datos completa, esta busca los sujetos, predicados y objetos que coinciden con esta declaración, exluyendo, al mismo tiempo, el resto de datos.
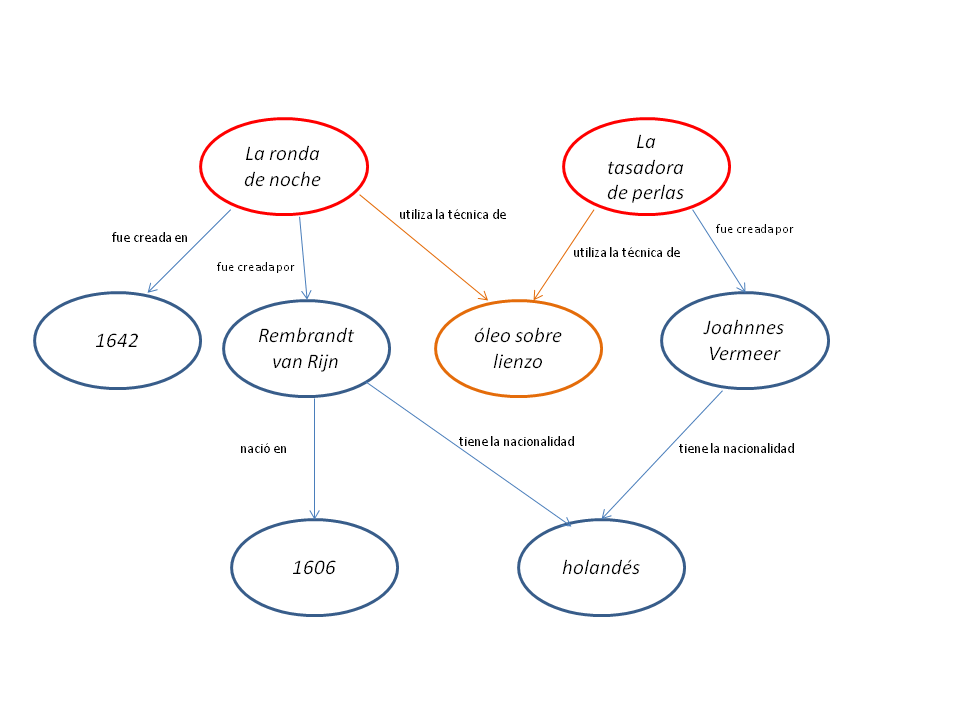
Visualización de la consulta SPARQL con los elementos mencionados en naranja y los elementos seleccionados (aquellos que nos serán devueltos en los resultados) en rojo. Diagrama reconstruido por Nuria Rodríguez Ortega.
Nuestros resultados podrían tener este aspecto:
| pinturas |
|---|
| La ronda de noche |
| La tasadora de perlas |
Ahora bien, lo que hace a RDF y a SPARQL herramientas tan potentes es su habilidad para crear consultas complejas que referencian múltiples variables al mismo tiempo. Por ejemplo, podríamos buscar en nuestra seudobase de datos RDF pinturas creadas por cualquier artista que fuese holandés:
SELECT ?artista ?pintura
WHERE {
?artista <es de nacionalidad> <holandesa> .
?pintura <fue creada por> ?artista .
}
En este ejemplo, hemos introducido una segunda variable: ?artista. La base de datos RDF devolverá todas las combinaciones conincidentes de ?artista y ?pintura que encajen en ambas declaraciones.
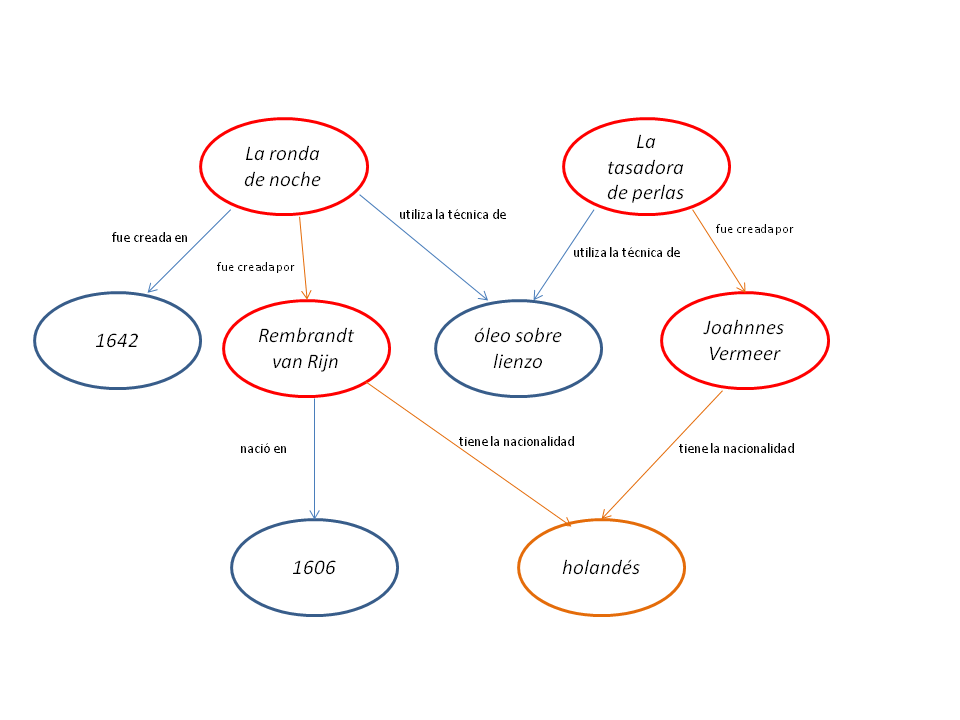
Visualización de la consulta SPARQL con los elementos mencionados en naranja y los elementos seleccionados (aquellos que serán recuperados en los resultados en rojo). Diagrama reconstruido por Nuria Rodríguez Ortega.
| artistas | pinturas |
|---|---|
| Rembrandt van Rijn | La ronda de noche |
| Johannes Vermeer | La tasadora de perlas |
URI y literales
Hasta ahora, hemos visto una representación facticia de RDF que utiliza un texto fácil de leer. Sin embargo, RDF se almacena principalmente en formato URI (Uniform Resource Identifiers), que separa las entidades conceptuales de sus etiquetas lingüísticas. (Ten en cuenta que una URL, o Uniform Resource Locator, es una URI accesible desde la web). En RDF real, nuestra declaración original:
<La ronda de noche> <fue creada por> <Rembrandt van Rijn>.
sería más parecido a lo siguiente:
<http://data.rijksmuseum.nl/item/8909812347> <http://purl.org/dc/terms/creator> <http://dbpedia.org/resource/Rembrandt> .
N.B. el Rijksmuseum todavía no ha desarrollado su propio sitio LOD, por lo que en esta consulta la URI responde únicamente a objetivos de demostración.
A fin de obtener una versión legible desde el punto de vista humano de la información representada por cada una de estas URI, lo que hacemos realmente es recuperar más declaraciones RDF. Incluso el predicado en esta declaración tiene su propia etiqueta literal:
<http://data.rijksmuseum.nl/item/8909812347> <http://purl.org/dc/terms/title> "La ronda de noche".
<http://purl.dc.terms/creator> <http://www.w3.org/1999/02/22-rdf-syntax-ns#label> "fue creado por".
<http://dbpedia.org/resource/Rembrandt> <http://xmlns.com/foaf/0.1/name> "Rembrandt van Rijn".
Como se puede observar, a diferencia de las URI que en esta consulta están enmarcadas por los signos <>, los objetos son cadenas de texto entrecomilladas. Esto es lo que se conoce como literales (literals). Los literales representan valores, mientras que las URI representan referencias. Por ejemplo, <http://dbpedia.org/resources/Rembrandt> representa una entidad que puede referenciar (y puede ser referenciada por) muchas otras declaraciones (fechas de nacimiento, discípulos, miembros de la familia, etc.), mientras que la cadena de texto "Rembrandt van Rijn" solo se representa a sí misma. Otros valores literales en RDF incluyen fechas y números.
Fijémenos ahora en los predicados de estas declaraciones, con nombres de dominio como purl.org, w3.org y xmlns.com. Estos son algunos de los numerosos proveedores de ontologías que ayudan a estandarizar el modo en que describimos relaciones entre bits de información como, “título”, “etiqueta”, “creador” o “nombre”. Cuanto más trabajemos con RDF/LOD, más proveedores de este tipo encontraremos.
Las URI pueden llegar a ser difíciles de manejar cuando se componen consultas SPARQL. Para simplificar este proceso se utilizan los prefijos (prefixes). Los prefijos son atajos que nos liberan de tener que escribir toda la larga cadena de caracteres que constituye una URI. Por ejemplo, recordemos el predicado para recuperar el título de La ronda de noche, http://purl.org/dc/terms/title>. Con los siguientes prefijos, solo necesitamos escribir dct:title cuando queramos utilizar un predicado purl.org. dct: representa la cadena completa http://purl.org.dc/terms, y 'title' simplemente se agrega al final de este enlace.
Por ejemplo, con el prefijo PREFIX rkm: que representa la cadena completa <http//data.rijksmuseum.nl>, agregado al inicio de nuestra consulta SPARQL, http://data.rijksmuseum.nl/item/8909812347 < se convierte en rkm:item/8909812347.
Debemos ser conscientes de que los prefijos se pueden asignar arbitrariamente a cualquier abreviatura que queramos; así, diferentes puntos de entrada (endpoints) pueden utilizar prefijos ligeramente diferentes para el mismo espacio de nombre (namespace) (por ejemplo: dct vs. dcterms para <http://purl.org/dc/terms>).
Términos para revisar
- SPARQL - Protocol and RDF Query Language - El lenguaje utilizado para interrogar bases de datos RDF u orientadas a grafos.
- RDF - Resource Description Framework - Un método para estructurar datos en forma de grafo o como una red de declaraciones conectadas más que como una serie de tablas.
- LOD - Linked Open Data (datos abiertos enlazados) - LOD son datos RDF publicados online en formato URI de modo que los desarrolladores pueden referenciarlos de manera fiable y sin ambigüedad.
- declaración - a veces denominada “tripleta”, una declaración RDF es una unidad de conocimiento que comprende sujeto, predicado y objeto.
- URI - Uniform Resource Identifier - una cadena de caracteres que identifica un recurso. Las declaraciones RDF utilizan URI para enlazar varios recursos. Una URL, o Uniform Resource Locator, es un tipo de URI que apunta a un determinado recurso en la web.
- literal - En las declaraciones RDF, algunos objetos no referencian recursos con una URI sino que vehiculan un valor, que puede ser un texto (
"Rembrandt van Rijn"), un número (5) o una fecha (1606-06-15). Estos objetos se conocen como literales. - prefijo - A fin de simplificar las consultas SPARQL, un usuario puede especificar prefijos que funcionan como abreviaturas de las URI completas. Estas abreviaturas, o QNAmes, se utilizan también en los espacios de nombre (namespaces) de los documentos XML.
Consultas basadas en casos reales
Todas las declaraciones para un objeto
Vamos a empezar nuestra primera consulta utilizando el punto de entrada SPARQL del British Museum. Un punto de entrada SPARQL es una dirección web que acepta consultas SPARQL y devuelve resultados. El punto de entrada del British Museum funciona como muchos otros: cuando accedemos a él a través de un navegador web, encontramos una caja de texto para componer las consultas.

Web del punto de entrada SPARQL del British Museum. Para todas las consultas de este tutorial, hay que asegurarse de haber dejado las casillas ‘Include inferred’ y ‘Expand results over equivalent URIs’ sin marcar.
Cuando empezamos a explorar una nueva base de datos RDF, resulta últil examinar, a modo de ejemplo, las relaciones que emanan de un objeto en concreto.
(Para cada una de las siguientes consultas, clica en el enlace “Run query” situado más abajo para ver los resultados. La puedes ejecutar tal y como está o modificarla antes. En este último caso, recuerda que es necesario dejar sin marcar la casilla “Include inferred” antes de ejecutar la consulta).
SELECT ?p ?o
WHERE {
<http://collection.britishmuseum.org/id/object/PPA82633> ?p ?o .
}
Con la orden SELECT ?p ?o, le estamos diciendo a la base de datos que nos devuelva los valores de ?p y ?o descritos en el comando WHERE {}. Esta consulta devuelve cada declaración para la cual nuestra obra de arte seleccionada, <http://collection.britishmuseum.org/id/object/PPA82633>, es el sujeto. ?p ocupa la posición central en la declaración RDF en el comando WHERE {}, por lo que esta devuelve cualquier predicado que coincide con la declaración, mientras que ?o, en la posición final, devuelve todos los objetos. Aunque yo las he nombrado como ?p y ?o, en realidad, tal y como se puede ver en el ejemplo inferior, es posible nombrar estas variables del modo que nosotros queramos. De hecho, será útil darles nombres significativos para las consultas complejas que siguen a continuación.
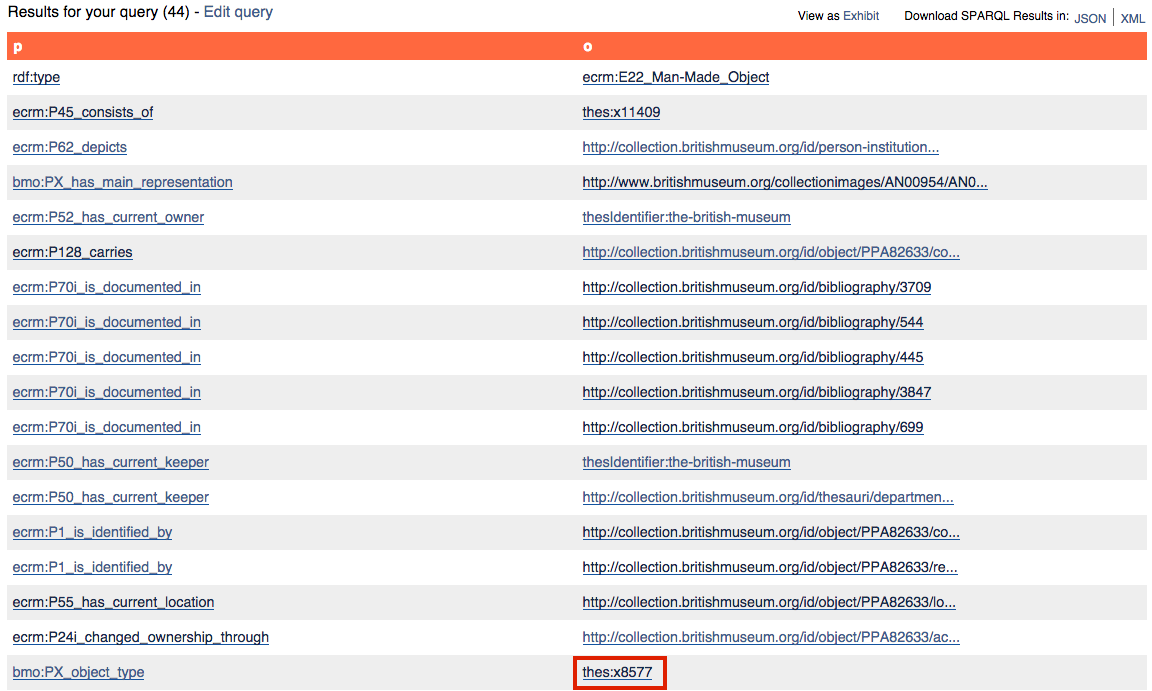
Listado inicial de todos los predicados y objetos asociados con una obra de arte en el British Museum.
El punto de entrada del Britism Museum formatea la tabla de resultados con enlaces para cada una de las variables, que son, en realidad, nodos RDF, por lo que clicando en cada uno de estos enlaces podemos ver todos los predicados y objetos para cada uno de los nodos seleccionados. Advierte que el British Musuem incluye automáticamente un amplio rango de prefijos SPARQL en sus consultas, por lo que encontraremos numerosos enlaces mostrados en su versión abreviada; si pasamos el ratón sobre ellos, podremos ver las URI sin abreviar.
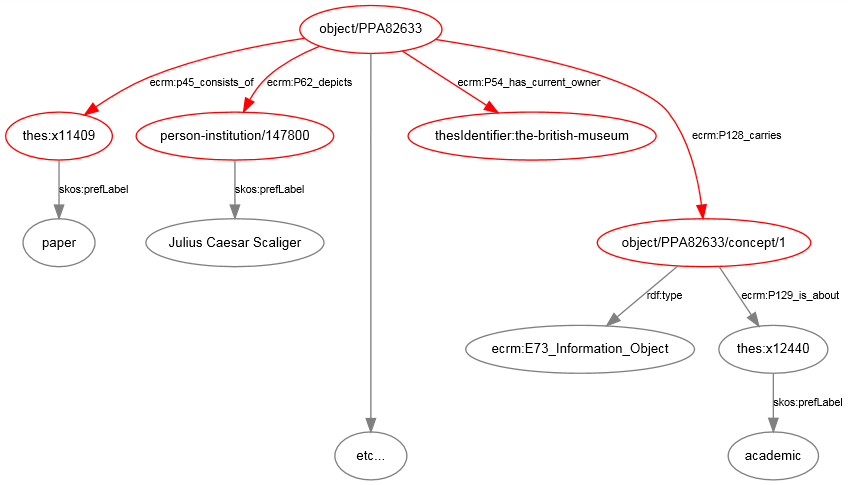
Visualización del conjunto de nodos recuperados a través de la primera consulta realizada a la base de datos del British Museum. Los elementos de este grafo coloreados en rojo se encuentran también en la tabla de resultados mostrada más arriba. Se han incluido niveles adicionales en la jerarquía para mostrar cómo esta obra en particular se encuentra conectada en el grafo general que constituye la base de datos del BM.
Veamos ahora cómo se almacena la información de tipo objeto: busca el predicado <bmo:PX_object_type> (marcado en la tabla anterior) y clica en el enlace thes:x8577 para acceder al nodo que describe el tipo de objeto “print” (grabado).
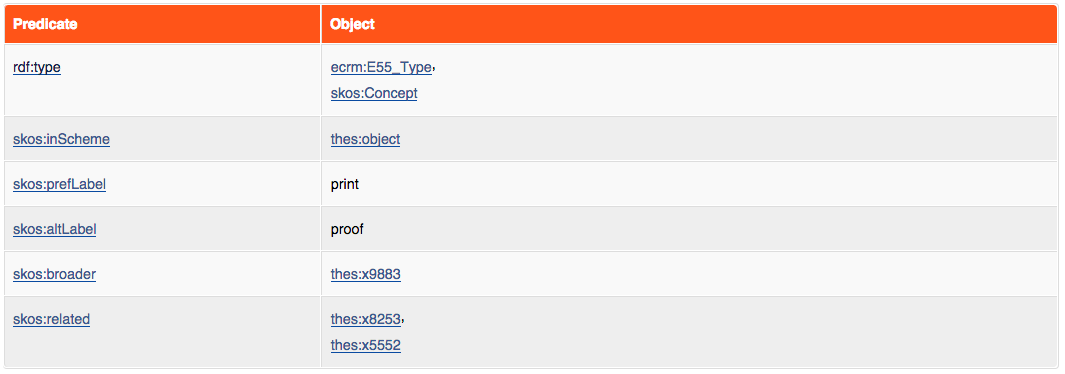
Página del recurso thes:x8577 (‘print’) en el conjunto de datos enlazados del British Museum.
Como se puede observar, este nodo tiene una etiqueta (label) en texto plano, así como enlaces a nodos del tipo “objetos artísticos” con los que se relaciona en el conjunto de la base de datos.
Consultas complejas
Para encontrar otros objetos del mismo tipo descritos con la etiqueta “print”, podemos invocar esta consulta:
PREFIX bmo: <http://www.researchspace.org/ontology/>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
SELECT ?object
WHERE {
# Busca todos los valores de ?object que tengan un "object type" dado
?object bmo:PX_object_type ?object_type .
# El "object type" debería tener la etiqueta "print"
?object_type skos:prefLabel "print" .
}
LIMIT 10
Run query / User-generated query
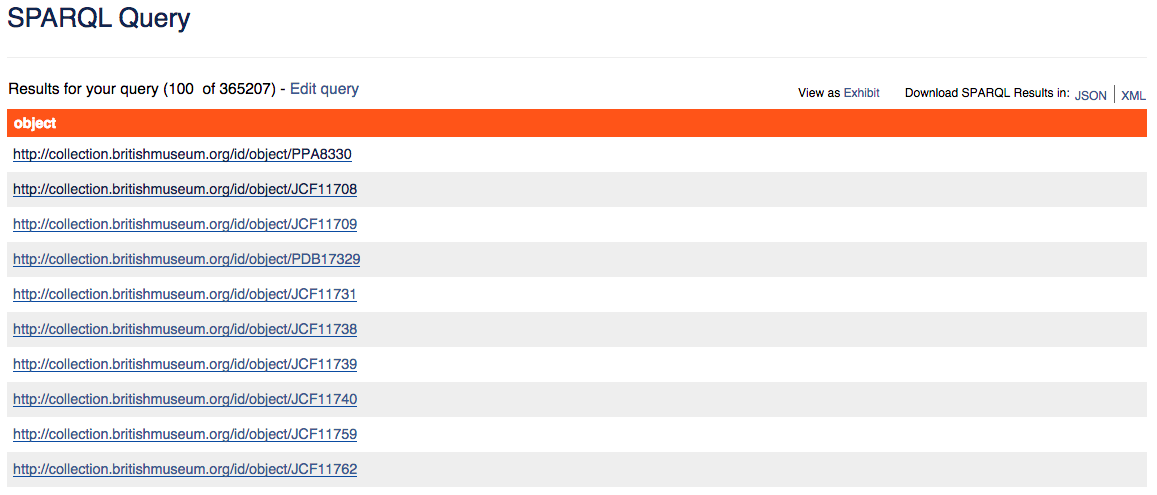
Tabla resultantes de nuestra consulta para todos los objetos del tipo ‘print’.
Recuerda que, dado que "print" funciona aquí como un literal, lo escribimos entrecomillado en nuestra consulta. Cuando se incluyen literales en las consultas SPARQL, la base de datos solo devuelve coincidencias exactas para estos valores.
Advierte también que, dado que ?object_type no se encuentra presente en el comando SELECT, este no se mostrará en la tabla de resultados. Sin embargo, resulta esencial estructurar nuestra consulta, porque es esto lo que permite conectar los puntos desde ?object con la etiqueta "print".
FILTER
En los ejemplos anteriores, nuestra consulta SPARQL ha buscado una coincidencia exacta para el tipo de objeto con la etiqueta “print”. Sin embargo, con frecuencia querremos encontrar valores literales que caen dentro de un determinado rango, como son las fechas. Para ello utilizaremos el comando FILTER.
Para localizar las URI de todos los grabados presentes en la base de datos del British Museum creados entre 1580 y 1600, necesitaremos, en primer lugar, averiguar dónde se almacenan en la base de datos las fechas en relación con los objetos, y entonces añadir referencias a estas fechas en nuestra consulta. De manera similar al procedimiento que hemos seguido de un único enlace para determinar un tipo de objeto, debemos ahora movernos a través de diversos nodos para encontrar las fechas de producción asociadas a un objeto dado:
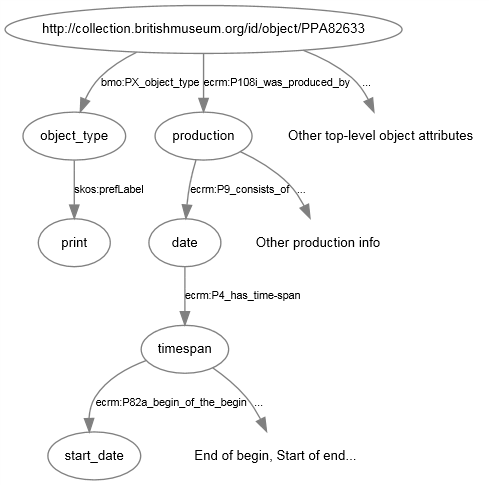
Visualización de la parte del modelo de datos del British Museum donde las fechas de producción están conectadas a los objetos.
PREFIX bmo: <http://www.researchspace.org/ontology/>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX ecrm: <http://www.cidoc-crm.org/cidoc-crm/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
# Recupera enlaces de objetos y fechas de creación
SELECT ?object ?date
WHERE {
# Utilizaremos nuestro comando previo para buscar solo
# objetos del tipo "print"
?object bmo:PX_object_type ?object_type .
?object_type skos:prefLabel "print" .
# Necesitamos enlazar diversos nodos para encontrar la
# fecha de creación asociada con un objeto
?object ecrm:P108i_was_produced_by ?production .
?production ecrm:P9_consists_of ?date_node .
?date_node ecrm:P4_has_time-span ?timespan .
?timespan ecrm:P82a_begin_of_the_begin ?date .
# Como se ve, es necesario conectar unos cuantos pocos de puntos
# para llegar al nodo de la fecha. Ahora que lo tehemos, podemos
# filtrar nuestros resultados. Dado que estamos filtrando por fecha,
# debemos agregar la etiqueta ^^xsd:date después de nuestra cadena de fecha.
# Esta etiqueta le dice a la base de datos que interprete la cadena
# "1580-01-01" como la fecha 1 de enero de 1580.
FILTER(?date >= "1580-01-01"^^xsd:date &&
?date <= "1600-01-01"^^xsd:date)
}
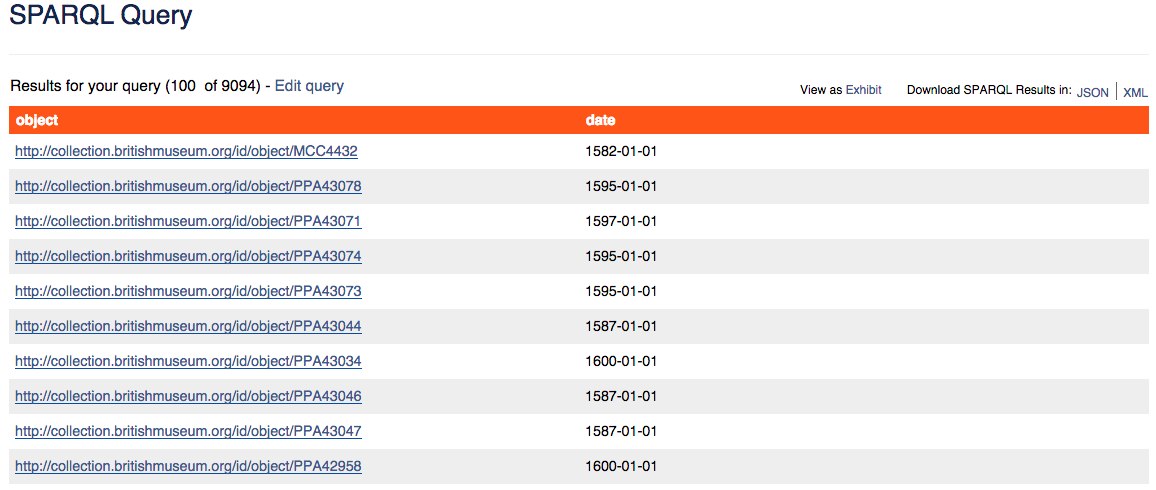
Todos los grabados del British Museum realizados entre 1580-1600.
Agregación
Hasta ahora, solo hemos utilizado el comando SELECT para recuperar una tabla de objetos. Sin embargo, SPARQL nos permite realizar análisis muchos más avanzados, como agrupaciones, cálculos y clasificaciones.
Pongamos por caso que estuviésemos interesados en examinar los objetos realizados entre 1580 y 1600, pero que asimismo quisiésemos conocer cuántos objetos de cada tipo tiene el British Museum en su colección. En vez de limitar nuestros resultados a los objetos del tipo “print”, en este caso utilizaríamos el operador COUNT para sumar los resultados de nuestra búsqueda en función del tipo al que pertenezcan.
PREFIX bmo: <http://www.researchspace.org/ontology/>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX ecrm: <http://www.cidoc-crm.org/cidoc-crm/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?type (COUNT(?type) as ?n)
WHERE {
# Es necesario que indiquemos la variable ?object_type,
# sin embargo, ahora no es necesario que esta coincida con el valor "print"
?object bmo:PX_object_type ?object_type .
?object_type skos:prefLabel ?type .
# De nuevo, filtraremos por fecha
?object ecrm:P108i_was_produced_by ?production .
?production ecrm:P9_consists_of ?date_node .
?date_node ecrm:P4_has_time-span ?timespan .
?timespan ecrm:P82a_begin_of_the_begin ?date .
FILTER(?date >= "1580-01-01"^^xsd:date &&
?date <= "1600-01-01"^^xsd:date)
}
# El comando GROUP BY designa la variable que se sumará,
# y el comando ORDER BY DESC() clasifica los resultados
# en orden descedente.
GROUP BY ?type
ORDER BY DESC(?n)
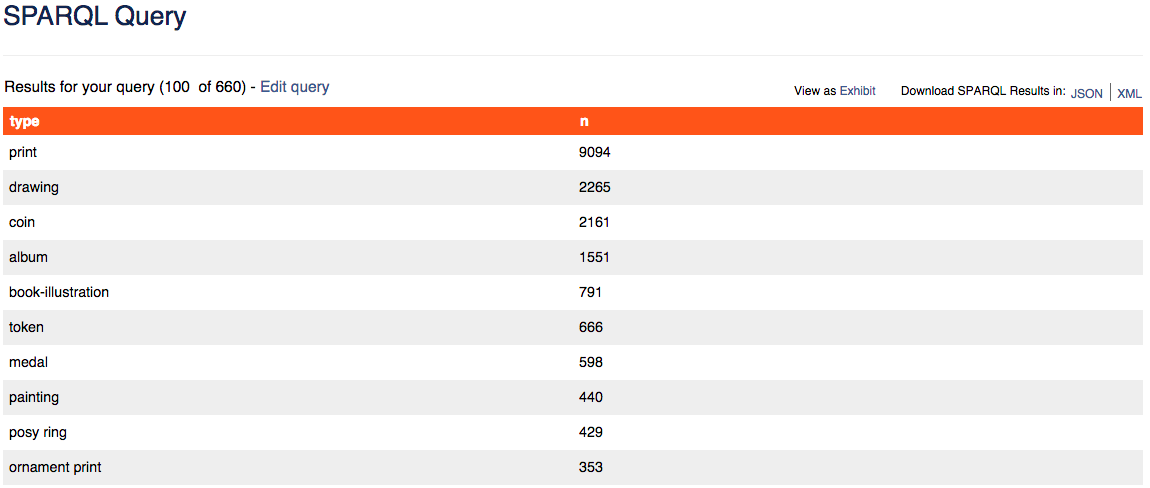
Recuento de los objetos producidos entre 1580 y 1600 según el tipo al que pertenecen.
Enlazando múltiples puntos de entrada SPARQL
Hasta ahora, hemos construido consultas que buscan patrones en un único conjunto de datos. Sin embargo, el escenario ideal al que aspiran los partidarios de LOD viene dado por la posibilidad de enlazar múltiples bases de datos, lo que permitirá realizar consultas mucho más complejas al estar estas basadas en el conocimiento distribuido que es posible extraer de diversos espacios web. No obstante, esto resulta más fácil de decir que de hacer, y muchos puntos de entrada (incluido el del British Museum) todavía no referencian recursos de autoridad externos.
Un punto de entrada que sí lo hace es el de Europeana. Europeana ha creado enlaces entre los objetos de sus bases de datos y los registros de personas en DBPedia y VIAF, los registros de lugares en GeoNames, y los conceptos resgistrados el Tesauro de Arte y Arquitectura (AAT) del Getty Research Institute. SPARQL nos permite insertar declaraciones SERVICE que ordenan a la base de datos “llamar a un amigo” y ejecutar una porción de la consulta en una base de datos externa, utilizando estos resultados para completar la consulta en la base de datos local. Si bien esta lección no se dentendrá en los modelos de datos de Europeana y DBPedia en profundidad, la siguiente consulta nos permite ver cómo funciona la declaración SELECT. Cada uno de los lectores puede ejecutarla por sí mismo copiando y pegando el texto de la consulta en el punto de entrada de Europeana. (A fin de que la consulta funcione, en el punto de entrada de Europeana se debe configurar el menú “Sponging” para “Retrieve remote RDF data for all missing source graphs”).
PREFIX ore: <http://www.openarchives.org/ore/terms/>
PREFIX edm: <http://www.europeana.eu/schemas/edm/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX dbo: <http://dbpedia.org/ontology/>
PREFIX dbr: <http://dbpedia.org/resource/>
PREFIX rdaGr2: <http://rdvocab.info/ElementsGr2/>
# Encuentra todos los ?object relacionados por alguna ?property con un ?agent nacido en una
# ?dutch_city
SELECT ?object ?property ?agent ?dutch_city
WHERE {
?proxy ?property ?agent .
?proxy ore:proxyFor ?object .
?agent rdf:type edm:Agent .
?agent rdaGr2:placeOfBirth ?dutch_city .
# En DBPedia, ?dutch_city está definida por pertenecer al país "Netherlands"
# La declaración SERVICE pregunta a
# http://dbpdeia.org/sparql qué ciudades pertenecen al país
# "Netherlands". La respuesta obtenida de esta subconsulta se utilizará para
# completar nuestra consulta originaria sobre los objetos
# presentes en la base de datos de Europeana
SERVICE <http://dbpedia.org/sparql> {
?dutch_city dbo:country dbr:Netherlands .
}
}
# Potencialmente, esta consulta puede devolvernos un elevado número de objetos, por lo que vamos
# a solicitar solo los cien primeros a fin de agilizar la búsqueda
LIMIT 100
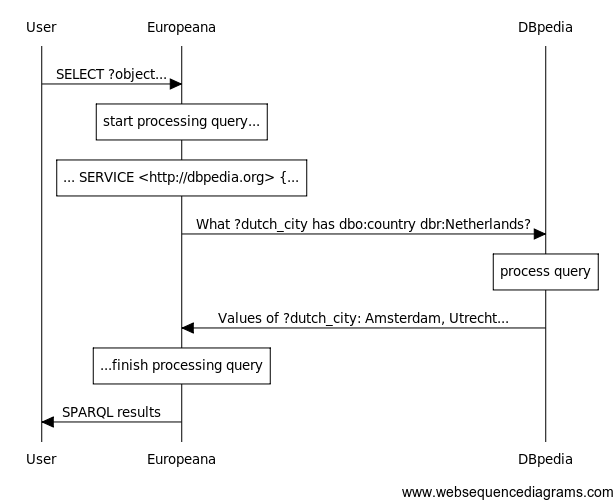
Visualización de la secuencia de la consulta de la solicitud SPARQL definida más arriba.
Una consulta interconectada como esta significa que podemos interrogar a Europeana sobre los objetos que cuentan con información geográfica (¿cuáles son las ciudades de Holanda?) sin necesidad de que Europeana tenga que almacenar y mantener esta información por sí misma. Es de esperar que, en el futuro, cada vez mayor cantidad de información LOD de carácter cultural esté enlazada con bases de datos autorizadas, como el ULAN (Union List of Artist Names) del Getty Research Institute. Esto permitirá, por ejemplo, que el British Museum “externalice” la información biográfica acudiendo a los recursos más completos del GRI.
Trabajando con resultados SPARQL
Una vez que hemos construido y ejecutado una consulta, ¿qué hacemos ahora con estos resultados? Muchos puntos de entrada, como el del British Museum, ofrecen un navegador web que devuelve resultados legibles para los humanos. Sin embargo, el objetivo de los puntos de entrada SPARQL (y para eso están diseñados) es devolver datos estructurados para ser utilizados por otros programas.
Exportar resultados en formato CSV
En la esquina superior derecha de la página de resultados del punto de entrada del BM, se encuentran enlaces para descargas en formato JSON y XML. Otros puntos de entrada también pueden ofrecer la opción de descargar los resultados en CSV/TSV; sin embargo, esta opción no siempre se encuentra disponible. Las salidas JSON y XML desde un punto de entrada SPARQL contienen no solo los valores devueltos por la declaración SELECT, sino también metadatos adicionales sobre tipos de variables e idiomas.
El procesamiento de la versión XML de los resultados se puede realizar con herramientas tales como Beautiful Soup (véase la lección correspondiente en The Programming Historian u OpenRefine). Para convertir rápidamente los resultados JSON desde un punto de entrada SPARQL en un formato tabular, yo recomiendo la utilidad de la línea de comando gratuita jg. (Para un tutorial sobre cómo utilizar programas de línea de comando, véase “Introduction to the Bash Command Line”). La siguiente consulta convertirá el formato especial JSON RDF en un fichero CSV, que podremos cargar en nuestro programa preferido para su posterior análisis y visualización:
jq -r '.head.vars as $fields | ($fields | @csv), (.results.bindings[] | [.[$fields[]].value] | @csv)' sparql.json > sparql.csv
Exportar resultados a Palladio
La popular plataforma de análisis de datos Palladio puede cargar directamente datos desde un punto de entrada SPARQL. En la parte inferior de la pantalla “Create a new project”, el enlace “Load data from a SPARQL endpoint (beta)” nos proporciona un campo para escribir la dirección del punto de entrada y una caja para la consulta propiamente dicha. Dependiendo del punto de entrada, podemos necesitar especifidar el tipo de fichero de salida en la dirección del punto de entrada; por ejemplo, para cargar datos desde el punto de entrada del British Museum, debemos utilizar la dirección http://collection.britishmuseum.org/sparql.json. Trata de pegar la consulta de agregación que utilizamos más arriba para el recuento de obras de arte según su tipología y clica en “Run query”. Palladio debería mostrar una tabla de previsualización como esta:
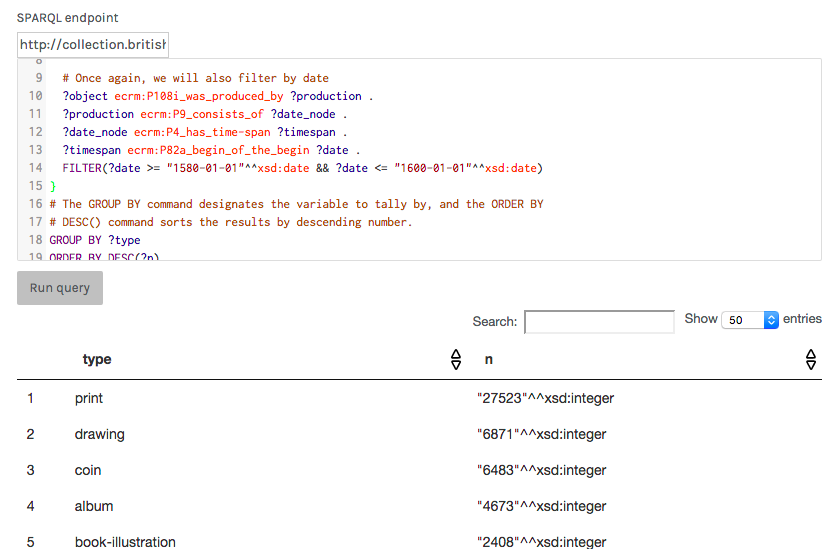
Interfaz de Palladio para las consultas SPARQL.
Después de previsualizar los datos devueltos por el punto de entrada, clica en en botón “Load data” en la parte inferior de la pantalla para empezar a trabajar con ellos. (Véase esta lección de Programming Historian para un tutorial más detallado sobre Palladio). Por ejemplo, podríamos realizar una consulta que devuelva enlaces a las imágenes de los grabados realizados entre 1580 y 1600, y representar estos datos como una galería de imágenes clasificadas por fecha:
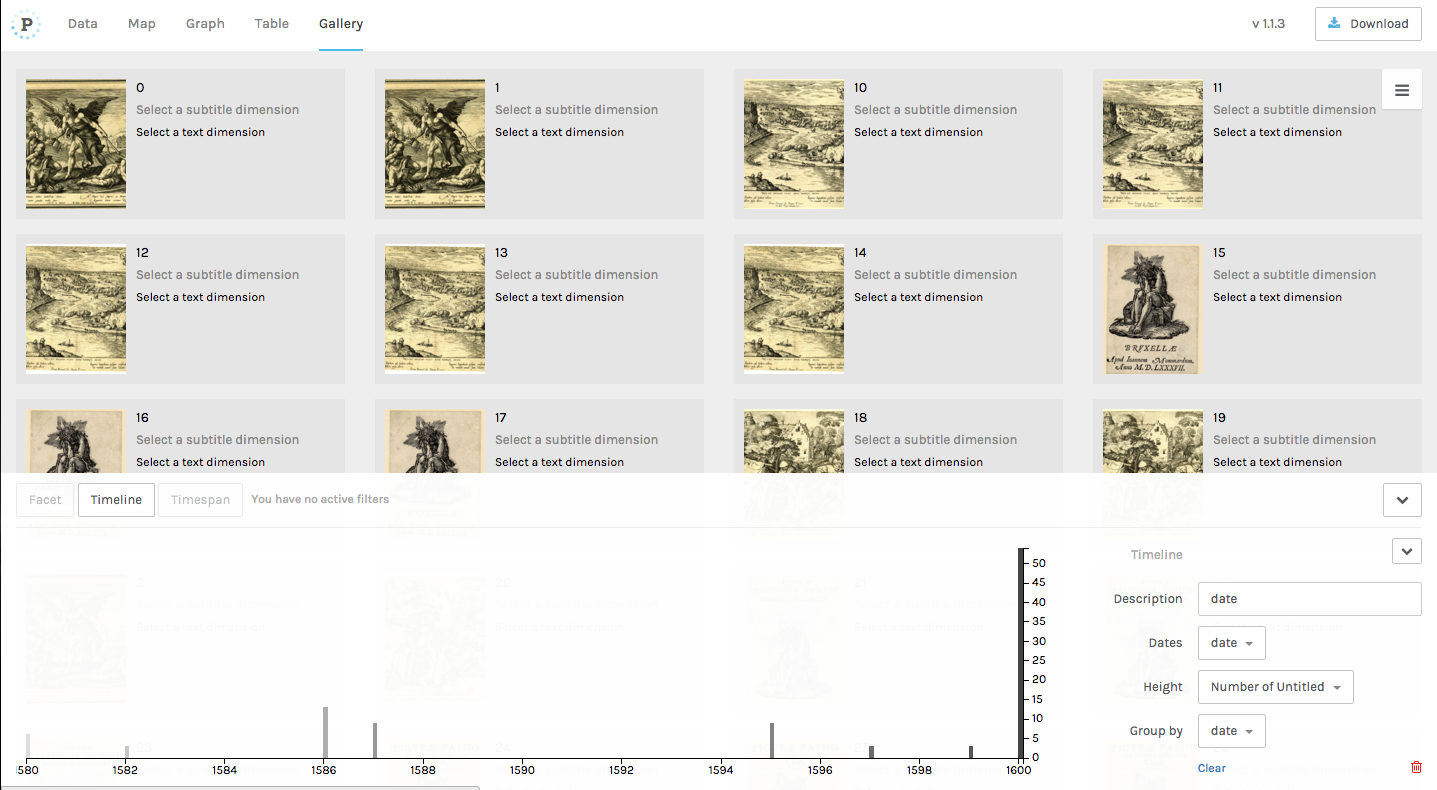
Galería de imágenes con línea de tiempo de sus fechas de creación generada utilizando Palladio.
Adviértase que Palladio está diseñado para funcionar con un conjunto relativamente pequeño de datos (del orden de cientos de miles de filas, no decenas de miles), por lo que pudiera ser necesario utilizar el comando LIMIT, que ya empleamos anteriormente en la consulta en el punto de entrada de Europeana, para reducir el número de resultados obtenidos y así evitar que el programa se quede bloqueado.
Lecturas adicionales
En este tutorial hemos examinado la estructura de LOD y hemos realizado un ejemplo real de cómo escribir consultas SPARQL para la base de datos del British Museum. También hemos aprendido cómo utilizar comandos de agregación en SPARQL para agrupar, contar y clasificar resultados más allá de la simple operación de listarlos.
Con todo, existen otras muchas maneras de modificar estas consultas, tales como introducir operadores OR y UNION (para describir consultas condicionales) y declaraciones CONSTRUCT (para inferir nuevos enlaces basados en reglas definidas), búsqueda de texto completo o llevar a cabo otras operaciones matemáticas más complejas que la del recuento. Para un informe más detallado de los comandos disponibles en SPARQL, véanse estos enlaces:
Tanto la web de Europeana como la del Getty Vocabularies ofrecen ejemplos extensos y bastante complejos de consultas que pueden constituir buenos recursos para comprender cómo buscar en sus datos: