Compare commits
20 Commits
50b6c6995e
...
master
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
239bb9ee6b | ||
|
|
565a117ad0 | ||
|
|
a6de3dbabd | ||
|
|
2b54cecdab | ||
|
|
f5353dd193 | ||
|
|
dc2e3dd59c | ||
|
|
3e3cb40067 | ||
|
|
999c2c1287 | ||
|
|
887cd28206 | ||
|
|
9148dba92e | ||
|
|
5f6b4e6d6e | ||
|
|
4f13947193 | ||
|
|
fd4c791931 | ||
|
|
211dd324ab | ||
|
|
d7ecee1664 | ||
|
|
ec2e9ea7cc | ||
|
|
1d1f044d80 | ||
|
|
6fe36b0d96 | ||
|
|
746dc01428 | ||
|
|
2c7eb133a9 |
2
.gitignore
vendored
@@ -5,3 +5,5 @@ cache
|
||||
output
|
||||
*.pid
|
||||
*.pyc
|
||||
_gen
|
||||
*/_gen
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 256 KiB After Width: | Height: | Size: 181 KiB |
@@ -1,3 +1,20 @@
|
||||
/*
|
||||
You can add your own custom styles here.
|
||||
*/
|
||||
*/
|
||||
.danger,
|
||||
.note,
|
||||
.warning {
|
||||
border-left-width: 0.8rem !important;
|
||||
}
|
||||
|
||||
.warning {
|
||||
border-left-color: #ffbb00 !important;
|
||||
}
|
||||
|
||||
.note {
|
||||
border-left-color: #4285f4 !important;
|
||||
}
|
||||
|
||||
.danger {
|
||||
border-left-color: #ee0000 !important;
|
||||
}
|
||||
|
||||
@@ -11,6 +11,8 @@ defaultContentLanguage = "en"
|
||||
# This will make .Summary and .WordCount behave correctly for CJK languages.
|
||||
hasCJKLanguage = false
|
||||
|
||||
enableEmoji = true
|
||||
|
||||
# Change it to your Disqus shortname before using
|
||||
#disqusShortname = "hugo-theme-stack"
|
||||
|
||||
|
||||
@@ -5,6 +5,9 @@ unsafe = true
|
||||
[goldmark.extensions.passthrough]
|
||||
enable = true
|
||||
|
||||
[goldmark.parser.attribute]
|
||||
block = true # default is false
|
||||
|
||||
# LaTeX math support
|
||||
# https://gohugo.io/content-management/mathematics/
|
||||
[goldmark.extensions.passthrough.delimiters]
|
||||
@@ -23,4 +26,4 @@ guessSyntax = true
|
||||
lineNoStart = 1
|
||||
lineNos = true
|
||||
lineNumbersInTable = true
|
||||
tabWidth = 4
|
||||
tabWidth = 4
|
||||
|
||||
@@ -78,8 +78,8 @@ enabled = true
|
||||
|
||||
## Comments
|
||||
[comments]
|
||||
enabled = false
|
||||
provider = "disqus"
|
||||
enabled = true
|
||||
provider = "giscus"
|
||||
|
||||
[comments.disqusjs]
|
||||
shortname = ""
|
||||
@@ -130,11 +130,11 @@ serverName = "cactus.chat"
|
||||
siteName = ""
|
||||
|
||||
[comments.giscus]
|
||||
repo = ""
|
||||
repoID = ""
|
||||
category = ""
|
||||
categoryID = ""
|
||||
mapping = ""
|
||||
repo = "balkian/balkian.github.com"
|
||||
repoID = "MDEwOlJlcG9zaXRvcnk2OTQxMTEw"
|
||||
category = "Blog comments"
|
||||
categoryID = "DIC_kwDOAGnpts4Cnm1b"
|
||||
mapping = "pathname"
|
||||
lightTheme = ""
|
||||
darkTheme = ""
|
||||
reactionsEnabled = 1
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# Related contents configuration
|
||||
includeNewer = true
|
||||
threshold = 60
|
||||
threshold = 10
|
||||
toLower = false
|
||||
|
||||
[[indices]]
|
||||
|
||||
10
content/categories/reflections/_index.md
Normal file
@@ -0,0 +1,10 @@
|
||||
---
|
||||
title: Reflections
|
||||
description: Longer posts that summarize my views or thoughts on a specific topic
|
||||
image:
|
||||
|
||||
# Badge style
|
||||
style:
|
||||
background: "#6340ac"
|
||||
color: "#fff"
|
||||
---
|
||||
@@ -1,9 +1,10 @@
|
||||
---
|
||||
title: Cheatsheets
|
||||
name: "cheats"
|
||||
slug: cheatsheets
|
||||
menu:
|
||||
main:
|
||||
weight: 4
|
||||
weight: 5
|
||||
params:
|
||||
icon: infinity
|
||||
---
|
||||
@@ -1,7 +1,9 @@
|
||||
---
|
||||
title: Linux
|
||||
title: Linux Cheatsheet
|
||||
slug: linux
|
||||
author: "Fernando Sánchez"
|
||||
description: Tips and tricks for GNU/Linux and Unix
|
||||
image: "img/linux.png"
|
||||
categories:
|
||||
- linux
|
||||
tags:
|
||||
55
content/cheatsheet/python.md
Normal file
@@ -0,0 +1,55 @@
|
||||
---
|
||||
title: Python
|
||||
description: Tips and useful libraries for python developers
|
||||
image: "img/python.png"
|
||||
categories:
|
||||
- programming
|
||||
tags:
|
||||
- python
|
||||
- programming
|
||||
---
|
||||
|
||||
## Interesting libraries
|
||||
|
||||
### [TQDM](https://github.com/tqdm/tqdm)
|
||||
|
||||
|
||||
From tqdm's github repository:
|
||||
|
||||
> tqdm means "progress" in Arabic (taqadum, تقدّم) and an abbreviation for "I love you so much" in Spanish (te quiero demasiado).
|
||||
|
||||
|
||||
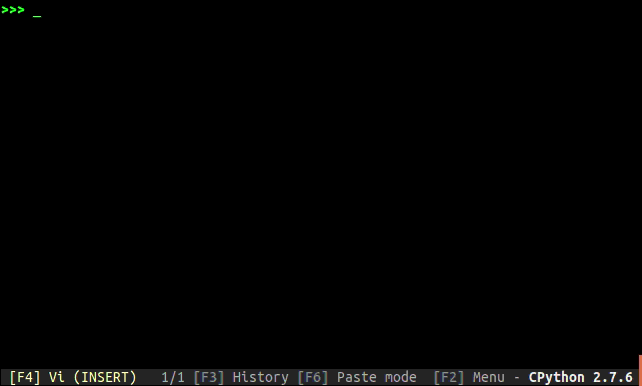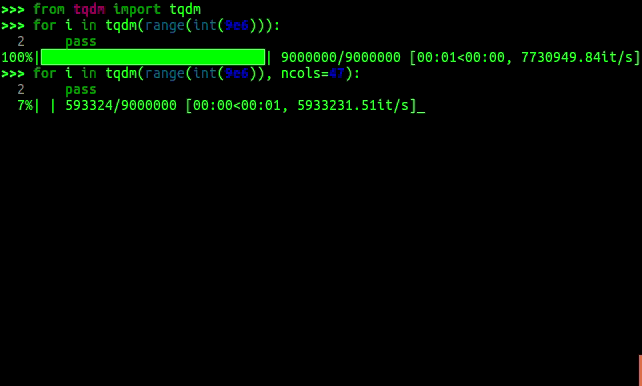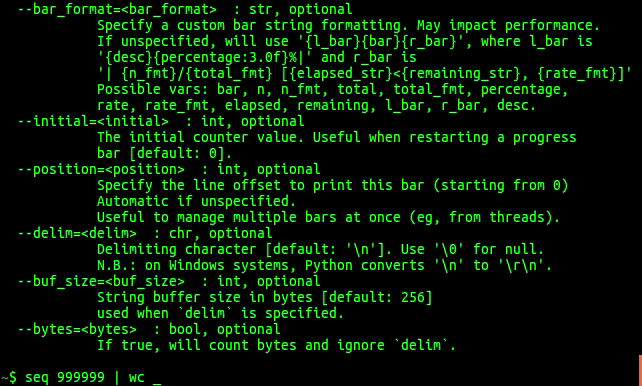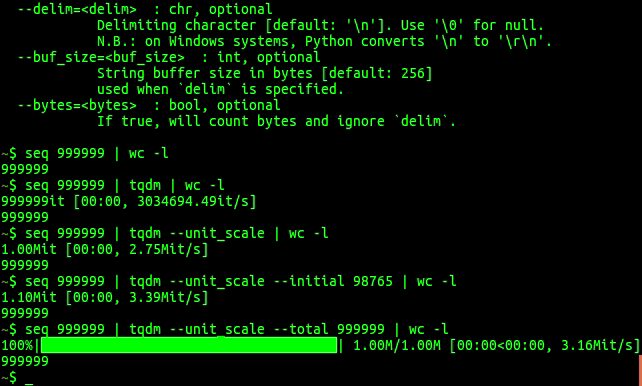
|
||||
|
||||
## Tools
|
||||
|
||||
### [uv](https://github.com/astral-sh/uv)
|
||||
|
||||
🚀 A single tool to replace pip, pip-tools, pipx, poetry, pyenv, twine, virtualenv, and more.
|
||||
⚡️ 10-100x faster than pip.
|
||||
* Provides comprehensive project management, with a universal lockfile.
|
||||
* Runs scripts, with support for inline dependency metadata.
|
||||
* Installs and manages Python versions.
|
||||
* Runs and installs tools published as Python packages.
|
||||
* Includes a pip-compatible interface for a performance boost with a familiar CLI.
|
||||
* Supports Cargo-style workspaces for scalable projects.
|
||||
* Disk-space efficient, with a global cache for dependency deduplication.
|
||||
* Installable without Rust or Python via curl or pip.
|
||||
* Supports macOS, Linux, and Windows.
|
||||
|
||||
### [pipdeptree](https://pypi.org/project/pipdeptree/)
|
||||
|
||||
A tool to generate a dependency tree from a virtualenv.
|
||||
|
||||
Useful to generate a clean `requirements.txt` or to clean up one that was generated with `pip freeze`.
|
||||
Usage:
|
||||
|
||||
```
|
||||
$ pipdeptree --exclude pip,pipdeptree,setuptools,wheel --warn silence | grep -E '^\w+' | tee requirements-clean.txt
|
||||
Flask==0.10.1
|
||||
gnureadline==8.0.0
|
||||
Lookupy==0.1
|
||||
pipdeptree==2.0.0b1
|
||||
setuptools==47.1.1
|
||||
wheel==0.34.2
|
||||
```
|
||||
36
content/page/about.md
Normal file
@@ -0,0 +1,36 @@
|
||||
---
|
||||
title: About
|
||||
slug: about
|
||||
readingTime: false
|
||||
comments: false
|
||||
menu:
|
||||
main:
|
||||
weight: 99
|
||||
params:
|
||||
icon: user
|
||||
---
|
||||
|
||||
Hello there, stranger! :wave:
|
||||
|
||||
## About me
|
||||
|
||||
My name is Fernando, and I like learning and solving hard problems.
|
||||
Especially when it comes to computers, engineering and languages.
|
||||
|
||||
I currently work at the Technical University of Madrid (UPM) as an assistant professor in the school of Telecommunications Engineering.
|
||||
You can check out my [previous projects](/page/projects), and [my publications](https://scholar.google.com/citations?user=JLNusZ8AAAAJ&hl=en).
|
||||
Feel free to get in touch through the comment section, an e-mail (`my first initial` `@sanchezrada.es`) or any other platform.
|
||||
I am always happy to help and collaborate.
|
||||
|
||||
## About this blog
|
||||
|
||||
I use this blog for future reference, to write down some of the lessons I learn so.
|
||||
I also see it as an exercise in reflection and sorting out my ideas.
|
||||
Although I mostly do this for myself, to keep some lasting notes for the future, I also do it in hopes it might help someone like me in the future.
|
||||
|
||||
Each post is an independent note.
|
||||
To keep some structure I will try to stick to general categories (e.g., programming, project management, linux), and add meaningful tags to help you and me find this information in the future.
|
||||
You may also use the [search bar](/search) if you are looking for something specific and wondering if I've covered it.
|
||||
For short thematically connected snippets and tips, I keep a dedicated section with [Cheatsheets](/cheatsheet).
|
||||
|
||||
|
||||
@@ -5,7 +5,7 @@ layout: "archives"
|
||||
slug: "archives"
|
||||
menu:
|
||||
main:
|
||||
weight: 2
|
||||
weight: 98
|
||||
params:
|
||||
icon: archives
|
||||
---
|
||||
---
|
||||
|
||||
@@ -1,21 +0,0 @@
|
||||
---
|
||||
title: Python
|
||||
description: Tips and useful libraries for python developers
|
||||
categories:
|
||||
- programming
|
||||
tags:
|
||||
- python
|
||||
- programming
|
||||
---
|
||||
|
||||
## Interesting libraries
|
||||
|
||||
### [TQDM](https://github.com/tqdm/tqdm)
|
||||
|
||||
|
||||
From tqdm's github repository:
|
||||
|
||||
> tqdm means "progress" in Arabic (taqadum, تقدّم) and an abbreviation for "I love you so much" in Spanish (te quiero demasiado).
|
||||
|
||||
|
||||

|
||||
@@ -1,19 +0,0 @@
|
||||
---
|
||||
title: Raspberry Pi
|
||||
description: Tools, links and configuration for your Raspberry Pi
|
||||
tags:
|
||||
- rpi
|
||||
---
|
||||
|
||||
## HDMI flickering
|
||||
|
||||
Avoid HDMI flickering/intermittent blanking on RPI with a 1400x1050 VGA monitor.
|
||||
|
||||
```python
|
||||
|
||||
hdmi_drive=2
|
||||
hdmi_group=2
|
||||
hdmi_mode=42
|
||||
disable_overscan=1
|
||||
config_hdmi_boost=7
|
||||
```
|
||||
@@ -1,14 +1,40 @@
|
||||
---
|
||||
title: Links
|
||||
description: Some pointers to useful resources.
|
||||
readingTime: false
|
||||
links:
|
||||
- title: GitHub
|
||||
description: My GitHub profile
|
||||
- title: My GitHub profile
|
||||
website: https://github.com/balkian
|
||||
image: https://github.githubassets.com/images/modules/logos_page/GitHub-Mark.png
|
||||
- title: gitea
|
||||
description: My gitea profile
|
||||
- title: GSI's GitHub
|
||||
description: I contribute to both public and private projects on the "Grupo de Sistemas Inteligentes" organization.
|
||||
website: https://github.com/gsi-upm
|
||||
image: "/img/gsi.png"
|
||||
- title: Dotfiles
|
||||
description: My configuration files.
|
||||
website: https://github.com/balkian/dotfiles
|
||||
image: https://github.githubassets.com/images/modules/logos_page/GitHub-Mark.png
|
||||
- title: Gists
|
||||
description: A collection of snippets that are/were useful for very specific tasks.
|
||||
website: https://github.com/balkian/gists
|
||||
image: https://github.githubassets.com/images/modules/logos_page/GitHub-Mark.png
|
||||
- title: Oxide and friends
|
||||
description: A weekly podcast about technology, from the guys behind the Oxide Computer Company.
|
||||
website: https://oxide-and-friends.transistor.fm/
|
||||
image: https://img.transistor.fm/e6CHJbwIxDiCUoVc9ylEKOnBKax85QPGwFI5Lezj2ho/rs:fill:800:800:1/q:60/aHR0cHM6Ly9pbWct/dXBsb2FkLXByb2R1/Y3Rpb24udHJhbnNp/c3Rvci5mbS9zaG93/LzI5MjU2LzE2NDg0/OTAxMDAtYXJ0d29y/ay5qcGc.webp
|
||||
- title: The Changelog Podcast(s)
|
||||
description: The Changelog podcast is software's best weekly news brief (Mondays), deep technical interviews (Wednesdays) & talk show (Fridays).
|
||||
website: https://changelog.com
|
||||
image: https://cdn.changelog.com/static/images/podcasts/podcast-medium-126fc11a345517eb5ae5708daee38390.png
|
||||
- title: Two's complement
|
||||
description: A podcast by Matt Godbolt and Ben Rady about programming.
|
||||
website: https://www.twoscomplement.org
|
||||
image: /img/twos-complement.png
|
||||
- title: My self-hosted gitea instance
|
||||
description: I use this for private projects, and to keep mirrors of important projects on GitHub, just in case.
|
||||
website: https://git.sinpapel.es/balkian
|
||||
image: https://git.sinpapel.es/assets/img/logo.svg
|
||||
|
||||
menu:
|
||||
main:
|
||||
weight: 4
|
||||
|
||||
@@ -1,8 +1,9 @@
|
||||
---
|
||||
title: Projects
|
||||
readingTime: false
|
||||
menu:
|
||||
main:
|
||||
weight: 1
|
||||
weight: 90
|
||||
params:
|
||||
icon: clock
|
||||
---
|
||||
@@ -24,6 +25,6 @@ Past Projects
|
||||
* [Marl](http://gsi.dit.upm.es/ontologies/marl): I updated this ontology, originally created by Adam Westerski, to make it compatible with the W3C's provenance ontology.
|
||||
* [Hermes](http://github.com/balkian/hermes): one of my first projects, developed together with David Pérez as the special custom assignment in one of our courses. Hermes is an affective bot designed to mimic the behavour of humans. It included a plug-in system for its sensors and actuators. The information from its sensors changed its emotional state, which was shown via its actuators. Among others, it could fetch inforation from Twitter or its host system and change the expressions of an external Face made with servo motors or speak via its Text-To-Speech software. For instance, it could detect it was running out of battery, showing a sad face and sending an alerting tweet. You can see it in action in these two youtube videos: [Part 1](http://www.youtube.com/watch?v=KnEYahPD9z4) and [Part 2](http://www.youtube.com/watch?v=lQZldCTPEJc).
|
||||
* [Maia](http://github.com/gsi-upm/maia): the Modular Architecture for Intelligent Agents is an evented agent architecture that aims to update the classical frameworks for intelligent agents with the concepts emerged from the Live Web.
|
||||
* [EESTEC.net](http://github.com/eestec/eestec.portal): the Plone based official portal of EESTEC. It has been my first and only experience with Plone. I fixed some bugs and implemented basic features.
|
||||
* [EESTEC.net](http://github.com/eestec/eestec.portal): the Plone based official portal of EESTEC. I fixed some bugs and implemented basic features.
|
||||
|
||||
For more information, check my list of public repositories in <a href="http://github.com/balkian"><i class="fab fa-github"> Github</i></a>.
|
||||
|
||||
@@ -7,7 +7,7 @@ outputs:
|
||||
- json
|
||||
menu:
|
||||
main:
|
||||
weight: 3
|
||||
weight: 2
|
||||
params:
|
||||
icon: search
|
||||
---
|
||||
---
|
||||
|
||||
93
content/post/2025-micropython-esp32.md
Normal file
@@ -0,0 +1,93 @@
|
||||
---
|
||||
title: "Installing Micropython on the Super Mini ESP32-S3"
|
||||
description:
|
||||
date: 2025-07-20T02:30:43+02:00
|
||||
image:
|
||||
math:
|
||||
license:
|
||||
hidden: false
|
||||
comments: true
|
||||
draft: false
|
||||
---
|
||||
|
||||
## Context
|
||||
|
||||
Many years ago I bought a "bargain" bluetooth scale.
|
||||
I wanted a way to automatically log my weight, and the Xiaomi equivalent was more than twice as expensive at the time.
|
||||
The problem is that it came with a very basic and somewhat sketchy software that required signing up, and none of the typical apps (openscale, gadgetbridge...) supported it.
|
||||
I looked at how to reverse engineer it, but I did not have much time back then, and I wrote it off as a "future project".
|
||||
Luckily, it had a screen, so I've been using it as a regular scale.
|
||||
I did not even bother to check the body composition metrics, because I got a very depressing reading of 35% body fat.
|
||||
|
||||
Flash forward to today, when I decided to finally work on it.
|
||||
In addition to trying nrfConnect, I installed the app to see the actual values..
|
||||
It turns out the composition data was completely off!!
|
||||
When a reading starts, the app needs to tell the scale some basic data about you (age, height, sex).
|
||||
Unfortunately, there is no way (that I know of) to set a default user, so when the phone is not connected, it goes back to the wildly inaccurate reading.
|
||||
|
||||
So, I decided to connect one of my idle ESP32 boards to it, to interface with the scale through bluetooth (sending the right user data) and logging the results somewhere through WiFi.
|
||||
|
||||
## The problem
|
||||
|
||||
Installing the firmware was not too difficult, after I got the board to properly register.
|
||||
|
||||
```
|
||||
❯ uv tool run esptool.py --port /dev/ttyACM4 erase-flash
|
||||
...
|
||||
Chip type: ESP32-S3 (QFN56) (revision v0.2)
|
||||
Features: Wi-Fi, BT 5 (LE), Dual Core + LP Core, 240MHz, Embedded Flash 4MB (XMC), Embedded PSRAM 2MB (AP_3v3)
|
||||
...
|
||||
❯ uv tool run esptool.py --port /dev/ttyACM4 --baud 460800 write_flash 0 ESP32_GENERIC_S3-20250415-v1.25.0.bin
|
||||
```
|
||||
|
||||
But then, I kept getting this error on boot: `OSError: (-24579, 'ESP_ERR_FLASH_NOT_INITIALISED')`.
|
||||
And I could not copy any files or install any packages.
|
||||
|
||||
After some research, I narrowed the possibilities to:
|
||||
|
||||
* A wrong partition table, most likely due to the fact that my board only has 4MB of flash.
|
||||
* Using an unsupported type of PSRAM (less likely)
|
||||
|
||||
## The solution
|
||||
|
||||
At this point, I could either try to compile the firmware with a custom partition (kind of tedious), or I could use the wonderful [mp-image-tool-esp32](https://github.com/glenn20/mp-image-tool-esp32) tool to check existing firmwares and modify partition sizes.
|
||||
|
||||
I confirmed my suspicion:
|
||||
|
||||
```
|
||||
❯ uv tool run mp-image-tool-esp32 ~/Downloads/ESP32_GENERIC_S3-20250415-v1.25.0.bin
|
||||
Running mp-image-tool-esp32 v0.1.1 (Python 3.12.11).
|
||||
Opening /home/j/Downloads/ESP32_GENERIC_S3-20250415-v1.25.0.bin...
|
||||
Found esp32s3 firmware file (8MB flash).
|
||||
Partition table (flash size: 8MB):
|
||||
╭──────────┬──────┬─────────┬──────────┬──────────┬──────────┬───────┬───────────╮
|
||||
│ Name │ Type │ SubType │ Offset │ Size │ End │ Flags │ │
|
||||
├──────────┼──────┼─────────┼──────────┼──────────┼──────────┼───────┼───────────┤
|
||||
│ nvs │ data │ nvs │ 0x9000 │ 0x6000 │ 0xf000 │ 0x0 │ (24.0 kB) │
|
||||
│ phy_init │ data │ phy │ 0xf000 │ 0x1000 │ 0x10000 │ 0x0 │ (4.0 kB) │
|
||||
│ factory │ app │ factory │ 0x10000 │ 0x1f0000 │ 0x200000 │ 0x0 │ (1.9 MB) │
|
||||
│ vfs │ data │ fat │ 0x200000 │ 0x600000 │ 0x800000 │ 0x0 │ (6.0 MB) │
|
||||
╰──────────┴──────┴─────────┴──────────┴──────────┴──────────┴───────┴───────────╯
|
||||
Micropython app fills 79.3% of factory partition (410 kB free)
|
||||
```
|
||||
|
||||
|
||||
```
|
||||
❯ uv tool run mp-image-tool-esp32 -f 4MB --resize vfs=2MB ESP32_GENERIC_S3-20250415-v1.25.0.bin
|
||||
❯ uv tool run esptool.py --port /dev/ttyACM4 --baud 460800 write_flash 0 ESP32_GENERIC_S3-20250415-v1.25.0-4MB-resize=vfs=2097152.bin
|
||||
```
|
||||
|
||||
After that, I was able to install new packages with `mpremote` and `mip`:
|
||||
|
||||
```
|
||||
uv tool run mpremote mip install aioble
|
||||
```
|
||||
|
||||
We can check that we are fully utilizing the 2MB of PSRAM:
|
||||
|
||||
```
|
||||
❯ uv tool run mpremote exec 'import gc;print(gc.mem_free(), "bytes")'
|
||||
2061456 bytes
|
||||
```
|
||||
|
||||
If you see much less than that, you are probably using the wrong variant (try `SPIRAM_OCT`).
|
||||
115
content/post/2025-uv.md
Normal file
@@ -0,0 +1,115 @@
|
||||
---
|
||||
title: "uv - One rust tool to rule all pythons"
|
||||
description:
|
||||
date: 2025-02-17T23:02:47+01:00
|
||||
image:
|
||||
math:
|
||||
license:
|
||||
hidden: false
|
||||
draft: false
|
||||
image: img/uv.png
|
||||
categories:
|
||||
- Programming
|
||||
tags:
|
||||
- python
|
||||
---
|
||||
|
||||
Long story short: I'm now using [uv](https://github.com/astral-sh/uv), and so should you.
|
||||
It is a great replacement for pip, pip-tools, pipx, poetry, pyenv, twine, virtualenv, and more.
|
||||
|
||||
<!--more-->
|
||||
|
||||
## Context
|
||||
|
||||
For years, my strategy to manage python projects has been a mix of a custom `setup.py`, several hand-crafted `requirements.txt` files (through `pip freeze`), a custom virtualenv per project, and multiple tools to upload to PyPI.
|
||||
Although this works, this setup has many drawbacks:
|
||||
|
||||
- It requires user intervention (creating a venv, sourcing it, handling new deps). This isn't ideal if you want new (probably inexperienced) users to use your projects.
|
||||
- On a similar note, the whole process needs to be well documented if you want other users to contribute or maintain the code.
|
||||
- Pinning dependency versions is finicky, and I've run into problems beause of that.
|
||||
- Creating a new project involves a template, or copying files from an older project.
|
||||
|
||||
Of course, this is nothing new.
|
||||
There is a whole site dedicated to [packaging your Python project](https://packaging.python.org/en/latest/).
|
||||
A plethora of different projects have come and go, with varying degrees of success.
|
||||
|
||||
## Alternatives (poetry)
|
||||
|
||||
About a year before trying `uv`, I tried to catch up with the ecosystem and get to know the `blessed new way`.
|
||||
However, the task proved to be a little more difficult, as the landscape is filled with a myriad of alternatives, each with their own set of drawbacks and detractors.
|
||||
Packaging has historically been a weak spot, in ironical contradiction to the Zen of Python's "There should be one-- and preferably only one --obvious way to do it",
|
||||
|
||||
I eventually settled on [poetry](https://python-poetry.org/).
|
||||
Mostly because it seemed like the most popular alternative.
|
||||
|
||||
There are many things I liked about it.
|
||||
First of all, having a convention for dependencies (`pyproject.toml`) and a tool that properly handles them was nice.
|
||||
It also removed the need to remember specific incantations to build and publish my Python projects.
|
||||
Lastly, I mixed it `poetry2nix` to create reproducible python environments using nix.
|
||||
This makes for a very powerful experience.
|
||||
|
||||
However, there were multiple hiccups.
|
||||
First of all, it took me some time to figure out which specific fields to use (each tool can define ad-hoc properties in a the `pyproject.toml` file), and some of them seemed redundant with the more generic ones.
|
||||
Full disclosure, this specific point might be a mistake on my side, and I do not remember the details.
|
||||
The second one is speed.
|
||||
(Re-)creating an environment took a non-negligible amount of time.
|
||||
|
||||
## Enter ~light~ `uv`
|
||||
|
||||
According to its repository, `uv `can replace pip, pip-tools, pipx, poetry, pyenv, twine, virtualenv, and more.
|
||||
Not only that, but it also claims to do that 10-100 times faster than pip.
|
||||
I must admit that it being written in rust was a another selling point for me, as I'm looking for excuses to collaborate in a decently-sized rust projejct.
|
||||
|
||||
Installing it is dead simple: simply download the binary (e.g., with curl) or run `pip install uv`.
|
||||
You won't need much more: `uv` seems to just do the right thing out of the box.
|
||||
And it does it really, really fast.
|
||||
The rest of the time it gets out of the way.
|
||||
|
||||
My only gripe so far is that I don't seem to find a built-in command to drop into a shell, but that is nothing that `uv run $SHELL` cannot fix.
|
||||
|
||||
|
||||
## Common operations
|
||||
### Initialize a repository
|
||||
|
||||
```
|
||||
uv init
|
||||
```
|
||||
### Adding dependencies
|
||||
|
||||
```
|
||||
uv add senpy
|
||||
```
|
||||
|
||||
### Running commands inside the environment
|
||||
|
||||
```
|
||||
uv run <COMMAND>
|
||||
|
||||
# e.g., run a shell using your python version and dependencies
|
||||
uv run $SHELL
|
||||
```
|
||||
|
||||
|
||||
### Dependency tree
|
||||
|
||||
```
|
||||
uv shell
|
||||
Resolved 44 packages in 1ms
|
||||
my-project v0.1.0
|
||||
├── fastapi[standard] v0.115.8
|
||||
│ ├── pydantic v2.10.6
|
||||
│ │ ├── annotated-types v0.7.0
|
||||
│ │ ├── pydantic-core v2.27.2
|
||||
│ │ │ └── typing-extensions v4.12.2
|
||||
│ │ └── typing-extensions v4.12.2
|
||||
│ ├── starlette v0.45.3
|
||||
│ │ └── anyio v4.8.0
|
||||
│ │ ├── exceptiongroup v1.2.2
|
||||
│ │ ├── idna v3.10
|
||||
│ │ ├── sniffio v1.3.1
|
||||
│ │ └── typing-extensions v4.12.2
|
||||
│ ├── typing-extensions v4.12.2
|
||||
│ ├── email-validator v2.2.0 (extra: standard)
|
||||
│ │ ├── dnspython v2.7.0
|
||||
...
|
||||
```
|
||||
62
content/post/a-reflection-on-rdf-and-the-semantic-web.md
Normal file
@@ -0,0 +1,62 @@
|
||||
---
|
||||
title: "A Reflection on RDF and the Semantic Web"
|
||||
description:
|
||||
date: 2025-03-04T19:19:53+01:00
|
||||
image:
|
||||
math:
|
||||
license:
|
||||
hidden: false
|
||||
comments: true
|
||||
draft: true
|
||||
---
|
||||
|
||||
I've been involved with semantic technologies almost for as long as I've been building software.
|
||||
Before my internship at the Intelligent Systems Group in 2009, I had done very little programming.
|
||||
This more or less coincidences with the rise of the semantic web.
|
||||
Given GSI's background with knowledge representation and web engineering, it should be no surprise that many projects back then involved RDF and semantic technologies.
|
||||
Moreover, most of the projects since then have been related to semantic technologies in some shape or form.
|
||||
|
||||
I remember being intrigued, then fascinated, with the idea of linked data.
|
||||
Representing knowledge in a way that allows both humans and machines to consume it seemed so obvious.
|
||||
In a way, it also tickled my "distributed systems" bone, with the whole "distributed and collaborative graph of knowledge".
|
||||
But it would not really get involved with the semantic web until years later, as part of my PhD thesis.
|
||||
|
||||
First, I was tasked with extending an existing vocabulary for sentiment analysis ([Marl](https://www.gsi.upm.es/ontologies/marl/)) to include provenance information (Prov-O).
|
||||
Then I applied the same ideas to define a new vocabulary for emotion analysis ([Onyx](https://www.gsi.upm.es/ontologies/onyx)).
|
||||
|
||||
Not long after that, I started working on a framework to allow laypeople to develop "semantic NLP services".
|
||||
It was already apparent to me that developing proper semantic services was out of reach (or interest) for the average programmer.
|
||||
There were too many concepts to learn (vocabularies, RDF-XML, turtle, inference...) without much push from industry to learn them.
|
||||
But I was still convinced that a semantic framework would lead to interoperability and flexibility.
|
||||
And those two benefits would lead to more adoption, ease of use, and more useful applications being developed.
|
||||
Besides, I was less focused on the long term viability of the project and more interested in the technical and usability challenges.
|
||||
|
||||
Building that framework has taught me very valuable lessons, which I'll probably get into in a separate post.
|
||||
On the topic of RDF and the semantic web, it made me deal with the reality of developing real semantic services that other consumers depend on, witnessing undergrads struggle with semantic annotations while developing their own services for their thesis, and building data annotation pipelines that rely on said services and their made-up annotations.
|
||||
|
||||
## The good
|
||||
|
||||
### Unique identifiers allow for federated knowledge graphs
|
||||
|
||||
### RDF's data model is neat
|
||||
|
||||
Modelling every fact as a triple is very powerful.
|
||||
Moreover, it makes it possible to represent your schema/vocabularies using the same raw elements.
|
||||
At the same time, it can be confusing for newcomers to grasp the difference between a vocabulary (TBox) and the data graph (ABox).
|
||||
|
||||
### SPARQL is quite versatile
|
||||
|
||||
### Linking data should provide a network effect
|
||||
|
||||
## The bad
|
||||
|
||||
### Defining vocabularies is tricky
|
||||
|
||||
### Vocabularies are not properly maintain
|
||||
|
||||
### Projects in the semantic space are not properly maintained
|
||||
|
||||
|
||||
## The ugly
|
||||
|
||||
### Nobody cares about it
|
||||
104
content/post/bridging-rdf-json-ld-and-dataclasses.md
Normal file
@@ -0,0 +1,104 @@
|
||||
---
|
||||
title: "Bridging RDF, JSON-LD and Dataclasses"
|
||||
description:
|
||||
date: 2025-02-26T23:22:59+01:00
|
||||
image:
|
||||
math:
|
||||
license:
|
||||
hidden: false
|
||||
comments: true
|
||||
draft: false
|
||||
categories:
|
||||
- programming
|
||||
tags:
|
||||
- rdf
|
||||
- json-ld
|
||||
- pydantic
|
||||
- python
|
||||
---
|
||||
|
||||
In the RDF world, data is expressed as a collection of triples.
|
||||
These triples can contain IRIs that may or may not be accessible or valid.
|
||||
And the use of these IRIs may or may not adhere to a vocabulary.
|
||||
Checking the validity of the IRIs and the semantics of the triples is an additional step.
|
||||
|
||||
## The `rdflib` way
|
||||
|
||||
`rdflib` only models IRIs, values and namespaces.
|
||||
Developers need to be cognisant of the URIs they are using, and the vocabularies being used.
|
||||
Prior to version 2.0, senpy followed a very similar model.
|
||||
It had a base class to represent a generic node.
|
||||
Each instance then gets its own automatically generated id, and will act like a normal dictionary, whose keys and values will be serialized as a JSON-LD dictionary.
|
||||
Multiple subclasses were also included to model specific types of node, mostly to provide convenience methods for the given subtype.
|
||||
Here is an example of a subclass, `Entity`.
|
||||
|
||||
```python
|
||||
entry = Entry()
|
||||
|
||||
entry['vocab:property'] = 25
|
||||
|
||||
print(entry.jsonld())
|
||||
```
|
||||
|
||||
Would print something like this:
|
||||
|
||||
```json
|
||||
{
|
||||
"@id": ":Entry_202505....",
|
||||
"@type": "prefix:Entity",
|
||||
"vocab:property": 25
|
||||
}
|
||||
```
|
||||
|
||||
Producing correct triples using this model requires using the vocabularies and URIs properly, with little to no tooling to enforce it.
|
||||
This poses a big problem for a tool like Senpy, which aims to make it easier for professionals without a background in RDF to build and consume semantic NLP ser
|
||||
If an attribute is not a URI and is not included in the global JSON-LD context, it will not generate a triple in the final graph.
|
||||
Moreover, there is way to enforce that the vocabularies and the
|
||||
|
||||
Pros:
|
||||
* Flexible/extensible
|
||||
* Lightweight. This is mostly JSON-LD in Python's clothing.
|
||||
* Naturally maps to both `rdflib` and writing `json-ld`
|
||||
|
||||
Cons:
|
||||
* Discoverability. Documentation and examples are needed to know which attributes to use
|
||||
* Error-prone. It is easy to misuse a property, or introduce typos
|
||||
* Tight coupling with semantics/RDF. One needs to know a thing or two about RDF, especially if new vocabularies or annotations need to be used.
|
||||
|
||||
## The object-oriented way
|
||||
|
||||
An obvious alternative to this problem in an object-oriented language like python is to use classes to represent our data model.
|
||||
These classes can define the specific attributes available, and typing annotations can serve both as a guide for the developer, and as a means to automatically
|
||||
validate objects at runtime.
|
||||
There are tools like [pydantic](https://pydantic.dev/) that make this process very simple.
|
||||
Then, we only need to define how your models should be serialized into JSON-LD.
|
||||
We can thoroughly test this serialization to ensure that the resulting object is correct and produces the right RDF graph.
|
||||
Going back to our previous example, we could define an Entry class as a dataclass, and define all the possible types of annotations as attributes.
|
||||
|
||||
This model works great when all the possible attributes are known ahead of time.
|
||||
But it starts to break when the model provided is not comprehensive enough, or customers of your library need to provide their own ad-hoc annotations / attribut
|
||||
es.
|
||||
This could be solved by encouring consumers of our library to define their own subclasses whenever they need to add new attributes.
|
||||
This works perfectly fine for serialization, but it breaks if your library needs to automatically deserialize these subclasses.
|
||||
It also breaks if different parts of the code need to add their own attributes on the same data at the same time.
|
||||
This was precisely the case of `senpy`, where entities are annotated by different plugins, each providing a different set of annotations.
|
||||
|
||||
Pros:
|
||||
* Discoverability. All possible attributes are known ahead of time, including their possible types.
|
||||
* Decoupling from RDF. Developers only need to know about the dataclasses provided. The mapping to the RDF world is already encoded in the dataclass.
|
||||
|
||||
Cons:
|
||||
* Rigidity. Adding new types of annotations requires modifying the models, in the main module.
|
||||
* Polymorphism.
|
||||
|
||||
|
||||
## A hybrid approach
|
||||
|
||||
Whichever solution is chosen in the end, it needs to:
|
||||
|
||||
* Make it easy and error-proof to add the most common types of annotations
|
||||
* Allow for additional annotations/attributes to be added
|
||||
* Allow for upgrades in the future. i.e., converting the most common custom annotations into built-in ones
|
||||
* Allow for deserialization of custom types
|
||||
* Allow multiple consumers to add their own annotations
|
||||
|
||||
465
content/post/efficient-collaboration.md
Normal file
@@ -0,0 +1,465 @@
|
||||
---
|
||||
title: "Tips for efficient collaboration"
|
||||
slug: efficient-collaboration
|
||||
description:
|
||||
date: 2025-03-05T09:25:54+01:00
|
||||
image:
|
||||
math:
|
||||
categories:
|
||||
- Reflections
|
||||
tags:
|
||||
- team
|
||||
- management
|
||||
license:
|
||||
hidden: false
|
||||
comments: true
|
||||
draft: false
|
||||
---
|
||||
|
||||
## Background
|
||||
|
||||
> TL;DR I work in academia. This post focuses on advice I'd give a younger me to be a more effective supervisor and project lead.
|
||||
{ .note }
|
||||
|
||||
My role in my research group has evolved from individual contributor to project lead that manages a team of multiple students.
|
||||
This often involves coordinatating with other senior researchers and their teams.
|
||||
|
||||
This post is a collection of advice I would have given myself back when I started this journey.
|
||||
It is also an excuse to reflect on these ideas I've been implicitly applying everyday, and maybe learn a few things more in the process.
|
||||
|
||||
In my field, projects are often tied to a specific grant or some sort of public funding.
|
||||
This means that the main concern of the lead is to ensure that the results at the end of the project match the description in the project proposal.
|
||||
It also typically means maximizing the number of publications related to the project and their overall impact.
|
||||
|
||||
To do so, most projects rely on three types of staff: a) senior researchers (post-doc); b) junior researchers (PhD students); and c) interns doing their bachelor's or master's thesis.
|
||||
The level of contribution is generally inversely propotional to the level of mastery of the contributor: PhD students design and develop the main contributions (both software and experimental) under the supervision of senior researchers (advisor/supervisor), and interns take care of tasks that are narrow in scope and not crucial to any academic contribution.
|
||||
For instance, a PhD student may develop a new model for text classification, and an intern will wrap that model in an HTTP service with a nice UI.
|
||||
When the service and UI part is intricate and has some potential academic merit, that task may be conducted by a PhD student as part of their thesis.
|
||||
That was precisely the case with Senpy, which was part of my PhD thesis, and it has since been used by dozens of students to develop services in the context of other research projects.
|
||||
|
||||
|
||||
## Reasons to form a team
|
||||
|
||||
In my opinion, a team has two advantages over a single contributor.
|
||||
The first one is that collaboration often generates **synergies**, leading to surprising and enriching results (a team is greater than the sum of its parts)
|
||||
Carefully selecting your team members and creating an environment that is conducing to these synergies is a topic on its own, and I will not get too deep into it here.
|
||||
|
||||
The second advantage can be summarized as **concurrency**: tasks can be tackled by more than one member.
|
||||
This often implies some sort of parallelism.
|
||||
Tasks tend to be split between different members, in hopes of speeding up the process.
|
||||
But it can also be beneficial to have concurrency even in the absence of parallelism: different members can take turns solving the same problem.
|
||||
This is common when the task requires exclusive access to a resource (e.g., performing an experiment on an expensive machine).
|
||||
|
||||
## Challenges of teams (of students)
|
||||
|
||||
Just like in computer science, coordination in a concurrent project involves a non-negligible overhead.
|
||||
The objective is to minimize this overhead.
|
||||
|
||||
I've really struggled with managing teams in the past.
|
||||
Given my context, I often attributed the failures to lack of time (having to juggle teaching and research), lack of training and preparation on the intern's side (they're often undergrads), lack of appeal or definition of the task (too academic-y), or any other external factors.
|
||||
|
||||
While all those aspects play an important role, some of them are out of our control as a project lead in academia: grants require a certain type of project and workflow, and the quality of our interns is bounded by the quality of our degrees.
|
||||
So I think it is more constructive to focus on things that we can control.
|
||||
In other words: we have to play the hand we're given.
|
||||
|
||||
Besides, there is no merit in achieving good results with excellent students/engineers.
|
||||
They would succeed on their own even if you weren't there.
|
||||
The real test for a good leader is succeeding with a subpar team.
|
||||
|
||||
|
||||
In that vein, I've reflected on my mistakes as a leader, and the inefficiencies of the teams around me.
|
||||
I'd classify my failures in the following areas:
|
||||
|
||||
* Delegation (and lack thereof). Piling up too many tasks and blocking progress.
|
||||
* Communication. Not having a coherent view of the state of affairs, the details of specific tasks, the general processes to follow, or the priorities of different tasks within a project.
|
||||
* Direction (or purpose). Not having a common direction
|
||||
|
||||
### Delegation
|
||||
|
||||
I have a tendency to become a bottleneck in any project I am involved in: many tasks end up depending on me, either directly or indirectly. In the concurrency metaphor, I become a lock for many tasks, and a single executor for the rest.
|
||||
This issue was not that apparent early on, when most of my work was as an individual contributor or I had the bandwidth to supervise and complete my tasks.
|
||||
|
||||
I think it is quite common to feel like delegating a task in these scenarios means:
|
||||
|
||||
1. Defining the task in advance
|
||||
2. Choosing an assignee for the task
|
||||
3. Setting a deadline for the task
|
||||
4. Explaining the task and the relevant context
|
||||
5. Replying to multiple questions by e-mail or in person. Extra points when the questions make you wonder if any part of the explanation was ever clear.
|
||||
6. Reviewing the results after the deadline
|
||||
7. Realizing the assignee misunderstood the task or delivered something not even close to what you agreed upon
|
||||
8. Going back to point 3.
|
||||
9. When you're unlucky or short on time: giving up and doing the task yourself
|
||||
|
||||
Many times, if felt like delegating tasks only lead to frustration and wasted time.
|
||||
Especially when compared to the alternative:
|
||||
|
||||
* Defining the task
|
||||
* Setting a deadline
|
||||
* Finishing the task
|
||||
* Profit
|
||||
|
||||
Luckily, some students and projects were an exception to this.
|
||||
They worked autonomously and delivered something beyond the minimum requirements.
|
||||
This reinforced my helplessness and the feeling that the problem was not being able to work with experienced engineers.
|
||||
|
||||
However, I now believe that the truth lies somewhere in between.
|
||||
Sometimes your circumstances make it quite hard or inefficient to delegate tasks.
|
||||
And some times may not be good candidates for delegation.
|
||||
But most of the times you can take advantage of having an extra pair of hands, you just have to do that effectively.
|
||||
|
||||
### Communication
|
||||
|
||||
Small teams rely on implicit knowledge more than they realize.
|
||||
Even more so if the team is made up of highly specialized people that have worked in the same environment with mostly the same people for years.
|
||||
|
||||
Communication is a broad term.
|
||||
It includes technical and concrete things such as how a certain task should be done.
|
||||
But it also includes broader things like etiquette, organizational values, and who is more willing to help you out on certain topics on a Friday afternoon.
|
||||
|
||||
Here, I would take a page out of Python's zen and recommend that "explicit is better than implicit".
|
||||
Implicit (or tacit) knowledge comes with a whole set of drawbacks:
|
||||
|
||||
* It makes onboarding new users harder. Without a common knowledge base, all knowledge transference has to rely on personal interactions. Even worse, those interactions are probably organized on the spot, and are likely to miss important points.
|
||||
* It makes you heavily reliant on your current members (and their memory).
|
||||
* It impedes proper evaluationn and progress, since they are not written anywhere.
|
||||
* It increases the likelihood of misunderstandings when two members have conflicting beliefs, and makes it harder to detect them until it is too late.
|
||||
* It makes contradictions and (unknowingly) changing your mind much more likely. It can happen to the best of us, especially if you are involved in too many projects. When contraditions happen often, your colleagues will learn not to rely on your opinion.
|
||||
|
||||
On the other hand, communication has to go both ways.
|
||||
This means that your newer members need to be able to communicate when something is going wrong or can be improved (backpressure).
|
||||
They should also feel free to talk about their motivation, state of mind, and feelings, **when appropriate**.
|
||||
That last part is quite subjective, of course.
|
||||
Try to find your - and your organization's - middle ground between "I don't care how you feel, just do your job" and "sure, you can go to the Maldives on short notice. Oh, and don't worry about not having met a deadline in months, I'm sure you're stressed and can use some vacation but will work remotely if we need you".
|
||||
|
||||
I personally feel a sweet spot is treating your coworkers like people, being empathetic and compassionate.
|
||||
Part of being a good coworker is fulfilling the duties and obligations you accepted when signing your contract.
|
||||
First and foremost, because not fulfilling them means someone else will have to work harder to make up for it.
|
||||
And, secondly, because doing our part is the only way to move the organization (and research) forward.
|
||||
|
||||
### Direction
|
||||
|
||||
By failure in direction I mean not keeping a consistent and shared set of general goals, principles and values in your organization.
|
||||
In order to really take part in any enterprise, you need to have a clear understanding of the objectives and motivation.
|
||||
When it comes to specific tasks, *what you're doing* is often not as important as the *why you're doing it*.
|
||||
In fact, there may be times where you aren't truly sure of what exactly it is that you are doing, but you trust the process and the motivation behind the task.
|
||||
|
||||
I've seen two failure modes in this regard.
|
||||
The first one is to not have a clear direction.
|
||||
The end result is that members of the team are not really that committed.
|
||||
If no other *why* is provided, we are only left with *because they pay me to do it*.
|
||||
And academia is not known to pay particularly well, to be honest.
|
||||
|
||||
The other mode is to provide contradicting or incompatible directions.
|
||||
This can be in a short period of time, leading to the impression that there isn't really any conviction in the message.
|
||||
But it can also be done over a longer period of time.
|
||||
That can be perfectly acceptable, provided that the change in direction is justified and compatible with the principles of the organization.
|
||||
|
||||
|
||||
Failure in direction is somewhat related to communication, but it is subtly different.
|
||||
An organization can excel at communication, but change their direction constantly.
|
||||
Arguably, a thorough communication strategy makes radical changes in direction less likely.
|
||||
On the one hand, a change in direction needs to be documented, which can be a pain.
|
||||
On the other hand, a written change is easier to spot and more likely to generate complaints.
|
||||
|
||||
|
||||
## Rules
|
||||
|
||||
I'd argue that the path to successfully managing a research team lies in roughly the following key goals:
|
||||
|
||||
* Fostering autonomy
|
||||
* Avoiding miscommunication
|
||||
* Optimizing your contribution
|
||||
|
||||
The remaining of the post will be a series of tasks or rules to achieve these goals.
|
||||
|
||||
> Most of these ideas probably generalize well to collaboration outside of academia, but I hesitate to make more general claims.
|
||||
{.warning}
|
||||
|
||||
### Fostering automony
|
||||
|
||||
The tips here are aimed at avoiding supervision overhead and training future leads.
|
||||
|
||||
#### Provide a (simplified version of the) bigger picture
|
||||
|
||||
Try to paint the bigger picture, even for menial tasks within large projects.
|
||||
For you, this may be the nth project you're involved in this year, but the new intern may not have even heard about European projects before.
|
||||
Going back to the idea of direction, it is easier to work on something if you know the context of your work.
|
||||
|
||||
Having a general idea of the project and the context of your task will also help you make decisions on your own.
|
||||
For instance, if I am told to develop a shiny new API for text classification, I may have to ask many questions: 1) what will be input look like?; 2) what should the parameters be?; 3) am I using POST or GET requests?; 4) should I return a JSON object or an XML?...
|
||||
What if, instead of that, I am also told this API will be used in the context of project X, that our organization will be the only consumers of the API, and they also give me a link to the project's docs.
|
||||
I may be able to figure out some of those answers on my own (e.g., by finding examples in the project's website), or decide that some questions are not vital at this point (e.g., if we are the only consumers, we can change from GET to POST if we need to much more easily).
|
||||
|
||||
One caveat here is that a link to the documentation or some vague words about the project do not constitute proper context.
|
||||
You are responsible for summarizing the important bits of the context, providing instructions on how to navigate the reference materials, and being open to answer questions that may arise in the exchange.
|
||||
|
||||
#### Do not discuss implementation details unless strictly necessary
|
||||
|
||||
There is a fine line between discussing a non-trivial implementation detail and bikeshedding for hours about class names and code best practices.
|
||||
For that reason, you should try to prioritize discussing high-level parts of the problem and the assignment, and trust the student to figure out the details on their own, or come back to you for clarification.
|
||||
|
||||
It is very common that students focus on very specific details when they are sharing their progress with their supervisors.
|
||||
They will generally try to start by showing snippets of code and their results.
|
||||
I find it helpful to remind them to explain their problems top-to-bottom, starting with a sentence or two about the context of their project, the description and motivation of the specific task they were doing, and the relationship with previous (and future) tasks.
|
||||
That usually helps figure out the level of understanding of the student, whether there are any conceptual errors, and whether the specific block or problem is really worth discussing during the meeting.
|
||||
|
||||
Some technical problems will warrant a discussion in detail, either due to their complexity or their importance to the project.
|
||||
In those cases, always limit the time you will spend on that specific issue ahead of time, and make sure to allow for some time at the end of the meeting to go back to any important high-level details.
|
||||
|
||||
If there are other students that worked on similar projects, do not hesitate to refer your new student to them.
|
||||
It can be an opportunity for them to collaborate, and for the original student to work on explaining and teaching technical issues.
|
||||
|
||||
#### Provide feedback
|
||||
|
||||
Make a point of evaluating the results of each student on every level, and provide constructive and actionable feedback to them.
|
||||
Even if no technical issues arise during the project, try to review the code and give some tips (e.g., formatting, code structure, DRY).
|
||||
Try to focus on bigger issues and enforcing best practices before nitpicking and giving feedback on small subjective improvements.
|
||||
|
||||
Make it clear when your feedback is objective/best practice (e.g., a function is deprecated) and when it is a matter of preference.
|
||||
If it is the latter, try to provide more than one alternative, to encourage them to think about it and make an educated decision.
|
||||
|
||||
|
||||
#### Take documentation and knowledge transfer seriously
|
||||
|
||||
Taking the time to write down basic documentation can save a lot of time in the long run.
|
||||
Besides, most of the job of mentoring a new student is lost when that student finishes their degree and leaves to find a job in industry.
|
||||
Good documentation can remain in your organization and be extended long after the intern is gone.
|
||||
|
||||
|
||||
This is very obvious for specific tools, whether internal or public.
|
||||
Good documentation means any new member can check the tool and use it without much assistance.
|
||||
Even better documentation helps newcomers contribute to the tool.
|
||||
Make sure to make it clear who to approach if something is missing from the documentation, and make it easier to do so than to make assumptions and use the tool incorrectly.
|
||||
|
||||
Writing documentation can be very time consuming, and sometimes it is hard to know exactly what things to focus on when writing the docs.
|
||||
You need to anticipate the needs of the future user.
|
||||
If you are short on time, a good strategy is to delegate the writing of the documentation.
|
||||
Instead of going into details, you can write a very barebones version and training a new user to use and contribute to your tool.
|
||||
Then, leave it up to the new user to extend the documentation, including more details and pitfalls.
|
||||
As a bonus, reading and fixing the docs will give you a better sense of how well that new user understands the tool, as well as possible improvements.
|
||||
|
||||
This tip also applies to more general areas such as machine learning, graph neural networks, or simulation.
|
||||
Just remember you do not need to reinvent the wheel in those cases.
|
||||
A simple summary and a list of references to expand on the topic could be more than enough.
|
||||
Make sure to also include any specifics that apply to your organization.
|
||||
For instance, point to repositories on github (public or private) that can be used to explore the topic, examples of similar projects in the domain, etc.
|
||||
|
||||
Identify what information is important for any new hire and present it to them as clearly as possible.
|
||||
Part of that information should be where and how common knowledge is stored and shared, should they need more information in the future.
|
||||
Make this documentation as easy to discover and consume as possible.
|
||||
Centralizing this common information in the form of a wiki is often a good idea.
|
||||
|
||||
Lastly, make it easy for any member of your organization to update this common documentation, and encourage them to do so.
|
||||
Whenever a member asks you something useful that is not documented, don't just answer the question.
|
||||
Take the time to add this information yourself (e.g., by copy-pasting your response) or task that member with expanding the documentation themselves once they find an answer.
|
||||
If your organization's culture does not encourage using these docs, they will quickly get outdated and fall out of use.
|
||||
|
||||
One example of taking this documentation approach really seriously is [Oxide (computer company)](https://oxide.computer/).
|
||||
They have a process they call [Request For Discussion (RFD)](https://rfd.shared.oxide.computer/), which they use to discuss and document both technical and organizational decisions.
|
||||
For instance, they have [RFDs on why they record every meeting](https://rfd.shared.oxide.computer/rfd/0537), [RFDs about their choice of database](https://rfd.shared.oxide.computer/rfd/0110), and even [an meta-RFD that discusses the motivation RFDs and how the process should work](https://rfd.shared.oxide.computer/rfd/0001).
|
||||
|
||||
|
||||
#### Trust your teammate's ability to learn
|
||||
|
||||
I've been bitten by this way too many times.
|
||||
Your students are probably more capable of learning than you think, especially if you have set up your documentation right.
|
||||
What they lack in experience, they make up for with free time, a (more) neuroplasticity and determination.
|
||||
|
||||
Sure, they will make mistakes (see the next section) and need some feedback (two sections above), but that is how we all learnt.
|
||||
|
||||
#### Use tools wisely
|
||||
|
||||
Your students probably have little experience with code versioning, reviewing processes, time management, etc.
|
||||
A good choice of tools and some training can go a long way and make your life much easier in the long run.
|
||||
It will also give your students a taste of what working in a bigger/real company feels like and a head start.
|
||||
|
||||
For instance, using git makes it easier to collaborate on code.
|
||||
It also ensures that your results will not be lost if your student's laptop gets stolen.
|
||||
|
||||
Using GitLab CI or GitHub Actions to deploy public services will provide more autonomy to your students.
|
||||
It will force them to commit working code, and it will make it easier to check their results and discuss the end result.
|
||||
|
||||
Using overleaf for theses has most of the advantages for collaboration as something like google docs, while being much more flexible and easier to produce formatting results.
|
||||
You may also use something like latex on a shared folder (e.g., nextcloud), although the chances of connflicts is higher, so be careful with documents that require live collaboration.
|
||||
In both cases, make sure to make the getting started experience as simple as possible: provide a sensible template, and only focus on simple features at first.
|
||||
|
||||
Also, on a related note, make sure every team member has a proper development setup.
|
||||
It does not matter which tool they use (VSCode, emacs, Jetbrains), as long as they are comfortable with it and they are able to focus on actual work.
|
||||
It helps to have a sensible default for your organization that is easy to set up and use, especially because most students do not have enough experience or skill with any particular tool.
|
||||
|
||||
|
||||
#### Encourage cooperation
|
||||
|
||||
Do not become the center of every conversation.
|
||||
If a topic can be discussed between two students, let them handle it on their own and get back to you if they need anything.
|
||||
|
||||
The ability to discuss with your peers and report only when needed will be extremely important for them in the future.
|
||||
They are also likely to discuss the topic more openly and more relaxed thhan with you (no matter how approachable you are).
|
||||
That might lead to valuable insights and improvements for your team and project.
|
||||
|
||||
Moreover, this attitude of open collaboration will help create those synergies we mentioned before, and make future projects easier and more enjoyable.
|
||||
|
||||
#### Reward proactivity
|
||||
|
||||
The whole point of this section is to get your team to work independently when possible.
|
||||
Be explicit about this goal to make sure it is clear to everyone.
|
||||
And encourage behavior that aligns with this goal, even on a small scale.
|
||||
|
||||
For instance, show interest when a student has shown initiative and researched something on their own, or when they go beyond the minimum requirements.
|
||||
Sometimes, you will notice that this research was not completely well oriented or it was not a very efficient use of time.
|
||||
Do not jump straight to criticize it.
|
||||
Compliment the attitude regardless, try to find the value in the results, and be gentle when providing feedback on why other topics or tasks were higher priority or a better choice.
|
||||
|
||||
#### Don't be a perfectionist
|
||||
|
||||
Perfect is the enemy of done.
|
||||
It is also the enemy of a happy co-worker.
|
||||
|
||||
Try to remember that you are dealing with students, and you were probably no better at their age.
|
||||
Besides, you probably delegated the task beause you did not have any spare time to do it yourself.
|
||||
`FIXME` is often better than `TODO`.
|
||||
|
||||
Take the opportunity to provide some feedback and teach them something useful.
|
||||
Some mistakes are also worth adding to your documentation, or presenting to other students in a presentation.
|
||||
|
||||
### Avoiding miscommunication
|
||||
|
||||
A common source of wasted effort and unnecessary back-and-forth is miscommunication.
|
||||
These are some tips to help keep everyone on the team informed and aligned.
|
||||
|
||||
#### Make priorities clear
|
||||
|
||||
All team members should understand the general priorities (project-wise) as well as the specific prorities of their assigned tasks.
|
||||
This will help inform their decisions when some other tasks inevitably come up, or the urgency of a task changes.
|
||||
|
||||
#### Define boundaries (and abstractions)
|
||||
|
||||
Once again, the goal is generally to achieve some sort of parallelism between your team members.
|
||||
In order to do that, they need to know how they will interact with each other.
|
||||
|
||||
On a more general level, this means knowing the responsibilities and scope of your work.
|
||||
|
||||
On a more specific level, it means knowing their dependency graph.
|
||||
In other words, whether the progress of one team member will depend on the results of another one.
|
||||
Whenever there is a dependency, the interface should be made very clear.
|
||||
This often takes the form of an API, a file with a given format, or a section of a document.
|
||||
|
||||
Take some time to define the boundary as precisely as needed at that point in the project.
|
||||
I would suggest having specific examples that you can discuss and modify.
|
||||
It is hard to discuss in the abstract, especially for inexperienced contributors.
|
||||
When in doubt, default to the simplest option (e.g., a common file vs using a database).
|
||||
Do not dwell too much on specific structural/representation details (e.g., which OWL vocabulary to use), but make sure that all the necessary bits are there.
|
||||
Converting a document or querying a document store (e.g., elasticsearch) instead of your file system is relatively easy, but making up non-existing data can be a challenge.
|
||||
|
||||
One type of failure I've seen quite frequently in this area is to be too fuzzy about the expected results from a team (or contributor), and refusing to discuss or provide examples.
|
||||
That tends to result in multiple iterations, each of them not-quite-what-you-wanted, and frustration in both sides.
|
||||
|
||||
|
||||
#### Be approachable
|
||||
|
||||
Did I wrote a whole section about autonomy? Yes.
|
||||
Is the end goal to do more and talk less? Also yes.
|
||||
Thing is, no process is perfect, and misunderstandings are bound to happen at some point.
|
||||
If your only response to questions is a grumpy face or a "read the freaking docs", your students will not alert you when something really needs your attention, and you will find out too late.
|
||||
For instance, the documentation may be unclear, or your processes may be inadvertedly alienating new members and making new hires harder.
|
||||
|
||||
Another way to be approachable is to be clear about your shortcomings, and whether something you are saying is negotiable and/or debatable.
|
||||
My rule of thumb is to err on the side of negotiable, and only be strict when it is really necessary (e.g., time constraints or an unproductive student).
|
||||
We are all more likely to finish our tasks if we feel them ours, if we a say in how and when to perform them.
|
||||
|
||||
Just to be clear, approachable does not mean you have to be their confident or their best friend.
|
||||
It also does not mean that it is okay to challenge or question you continuously.
|
||||
Some times it is okay to simply say "just do as I say".
|
||||
|
||||
#### Review frequently
|
||||
|
||||
One type of review is individual.
|
||||
It involves reviewing code on github, or reading deliverables and papers on overleaf.
|
||||
It can help catch misunderstandings, and measure the true rate of progress in the individual tasks.
|
||||
The other type of review is done as a group, by going through the key progress and action points.
|
||||
This type of review helps everyone stay on the same page, and catch any general drifts in the project, such as misaligned priorities.
|
||||
|
||||
The frequency of each type of review depends on the specific nature of the project, the types of tasks being performed by the student, and your confidence on the student's abilities.
|
||||
|
||||
|
||||
### Optimizing your contribution
|
||||
|
||||
Tips on optimizing your contribution to the team.
|
||||
|
||||
#### Prioritize, prioritize, prioritize
|
||||
|
||||
Part of your job as a project lead is to identify the main goals in a project and to prioritize the tasks that will lead you there.
|
||||
On the other hand, you are part of a research group, and you should be actively involved in its health and future.
|
||||
Lastly, you are also in charge of the life-long project that is your research career.
|
||||
|
||||
In all these cases, your goal should be to identify the long term goals, come up with a sound strategy, and prioritize the tasks that will lead you and your group there.
|
||||
Keeping your priorities straight will help you make steady progress, and avoid bikeshedding and changing goalposts.
|
||||
It will also help you steer your progress in the right direction, since we all have limited time and effort and can't do everything at once.
|
||||
|
||||
The fact that your time is limited also means that you will need to decide how to prioritize these three roles.
|
||||
I've listed them in increasing level of importance for me.
|
||||
It means that it is okay to focus on a specific project for a while, but if progress in your career is stalled - usually through publication - you need to reevaluate and concentrate your efforts on that.
|
||||
|
||||
#### Be okay with (short-term) inefficiencies
|
||||
|
||||
I've personally struggled with delegating tasks that will take me orders of magnitude less work than they will a student.
|
||||
Thing is, most tasks will fall under this category, and your time is limited, so you have to delegate if you want to have time for more important matters.
|
||||
If you never delegate any tasks, you are not allowing your team to learn and catch up on whatever technical skills are required.
|
||||
Besides, you are not improving yourself on the managerial side of things.
|
||||
It turns out delegating is hard, it requires a whole set of non-technical skills.
|
||||
I suspect this is oftentimes the reason we don't do delegate in the first place: delegating is hard, and technical tasks are usually more straightforward, so we just don't want to do the work.
|
||||
|
||||
#### Don't neglect training
|
||||
|
||||
You are a senior researcher.
|
||||
You probably know how to solve problems in your domain quite efficiently.
|
||||
In my case, that means processing data and developing code.
|
||||
|
||||
That means I could dedicate my days to processing data and developing new code for my group.
|
||||
That group would likely be used in multiple projects.
|
||||
However, there is a hard limit to how much code I can push out in a day, especially if you take into account other obligations such as teaching.
|
||||
|
||||
A wiser strategy would be to set aside some of that coding time to instead help students become better programmers.
|
||||
Firstly, because those students will be thankful and more motivated to work than when they are left to learn on their own without much guidance.
|
||||
Secondly, because those students will then be more prepared to help me out if I delegate a task to them.
|
||||
And, lastly, because these students have a whole life in fron of them.
|
||||
A life full of big projects of their own, and contributions to society.
|
||||
That little training time can have a compounding effect in the future.
|
||||
|
||||
|
||||
#### Set a time limit for your interactions in advance
|
||||
|
||||
Really long slots can easily lead to bikeshedding and going unnecessarily deep into implementation details, which is clearly an inefficient use of your time.
|
||||
Even worse, our attention span and memory are finite, so longer and dense meetings can lead to fatigue and to missing or dilluting important points in the conversation.
|
||||
|
||||
For these reasons, be very clear about these time limits, and do not extend these meetings unless it is strictly necessary.
|
||||
You can always schedule a new meeting, but be sure to provide enough time in between to process the results of the meeting, reflect and prioritize.
|
||||
|
||||
## Beyond your team
|
||||
|
||||
The previous points and rules focus mostly on actions that can be applied within your team, and that you can fully control.
|
||||
But teams rarely work in isolation, you will most likely
|
||||
In order to be effective, you also need to coordinate with other teams/groups, and more generally work on your organization's culture and sense of belonging.
|
||||
|
||||
Many of the aspects I talked about in the team section apply here.
|
||||
For instance, the obsession with documentation can - and should - be applied organization-wise.
|
||||
The same goes for defining boundaries and using concrete examples when collaborating with other teams.
|
||||
For most intents and purposes, you can treat other teams as another contributor to your team.
|
||||
Just one that will be more costly and slow to interact with.
|
||||
|
||||
If possible, I'd try to apply the rule about focusing on the big picture, and limit most meetings to those that strictly need to be involved.
|
||||
Avoid involving whole teams in discussions when the broad strokes have not been defined yet.
|
||||
The responsibilities will be dilluted in a bigger group, it will be harder to avoid misunderstandings and easier to bikeshed.
|
||||
|
||||
On the organization's side, I would suggest having an honest conversation about your core principles.
|
||||
I really liked [Bryan Cantrill's talk about principles of technology leadership](https://www.youtube.com/watch?v=9QMGAtxUlAchttps://www.youtube.com/watch?v=9QMGAtxUlAc).
|
||||
He goes deep into the effects that principles have had on well known companies, and how to go about defining your company's principles.
|
||||
I think that writing down your principles forces you to be conscious about their trade-offs, and to be explicit about your choices and attitudes.
|
||||
|
||||
More generally, try to define (light) processes that reward and facilitate behaviors you find positive, such as writing documentation and being proactive.
|
||||
And try to discourage the opposite type of behavior as soon as possible, to make correcting them easier.
|
||||
Apply the ideas of frequent evaluation and feedback, openness and honesty in every aspect of your organization.
|
||||
|
||||
|
||||
|
||||
@@ -1,17 +1,14 @@
|
||||
---
|
||||
title: Emacs
|
||||
description: Configuration files and tricks for emacs
|
||||
title: "Emacs: show plain text version"
|
||||
#image: "img/emacs.png"
|
||||
tags:
|
||||
- emacs
|
||||
- org
|
||||
- productivity
|
||||
- lisp
|
||||
|
||||
- snippet
|
||||
---
|
||||
|
||||
|
||||
## Show plain text version
|
||||
|
||||
<!--more-->
|
||||
|
||||
```lisp
|
||||
101
content/post/home-manager.md
Normal file
@@ -0,0 +1,101 @@
|
||||
---
|
||||
title: "NixOS and Home Manager"
|
||||
description:
|
||||
date: 2025-08-31T18:53:25+02:00
|
||||
image: /img/nixos.svg
|
||||
math:
|
||||
license:
|
||||
hidden: false
|
||||
comments: true
|
||||
draft: false
|
||||
---
|
||||
|
||||
Nix is a declarative package manager (and its main language) that allows for reproducible environments (i.e., files in a folder).
|
||||
|
||||
One of the cool things about nix is that you can use it to run a package without installing it permanently in your system.
|
||||
For instance, I recently needed the `readelf` utility and it wasn't installed in my system, so I ran:
|
||||
|
||||
```
|
||||
nix run 'nixpkgs#toybox' -- readelf -l /home/j/.local/share/uv/python/cpython-3.10.11-linux-x86_64-gnu/bin/python | grep interpreter
|
||||
```
|
||||
|
||||
That's it.
|
||||
No need to deal with dependencies, incompatibilities, or to uninstall the package once you no longer need it.
|
||||
|
||||
NixOS is a Linux Operating system that uses this package manager and system configuration (e.g., users, network interfaces, etc.) defined in the Nix language to create reproducible systems.
|
||||
|
||||
Home-manager takes the concepts from NixOS to user-space, allowing you to define your personal environment (i.e., home).
|
||||
It can be used on any system that supports the Nix package manager (e.g., Linux, Mac and Windows).
|
||||
|
||||
There is a lot to like
|
||||
|
||||
## Context
|
||||
|
||||
(Last year)[https://github.com/balkian/dotfiles/commit/fa7041ff8bde6c5288ad55db6b0d61ed593bbccc] I started experimenting with nix and home-manager to configure my environments.
|
||||
The context is that for some years now I've been switching devices quite frequently.
|
||||
It started when my main laptop died (DELL!!), I started using a desktop for most of my work, but I also needed a laptop to teach.
|
||||
One thing led to another, and I ended up using vanilla Ubuntu or EndeavourOS installations with Gnome and very minimal customization.
|
||||
That in itself is not wrong.
|
||||
The thing is that, before that, I was a [tinkerer with a customized environment](https://github.com/balkian/dotfiles).
|
||||
|
||||
|
||||
1. I was being inefficient (and I felt it)
|
||||
2. That inefficiency turned some easy things into a chore
|
||||
3. This made work in general less enjoyable.
|
||||
3. As a result, I became even less productive
|
||||
|
||||
The idea was to get back to a usable terminal and editor setup with minimal
|
||||
|
||||
|
||||
## NixOS
|
||||
|
||||
I've only been running NixOS for three days now, but so far I like the experience.
|
||||
My approach is to keep the system definition as simple as possible, and rely on home-manager to install and configure most of my tools.
|
||||
The basics would be:
|
||||
|
||||
* Network configuration
|
||||
* System users
|
||||
* Desktop environment (wayland and multiple DE's)
|
||||
|
||||
All that goins into my `/etc/nixos/configuration.nix`, and then I do:
|
||||
|
||||
```
|
||||
sudo nixos-rebuild switch
|
||||
```
|
||||
|
||||
If it fails, nothing is changed in your system.
|
||||
If it works, most of the changes will have been applied (e.g., new services started, others stopped).
|
||||
The previous configuration does not disappear: you can roll back to it manually or when booting your system.
|
||||
|
||||
## Home-Manager
|
||||
|
||||
Here's where most of my configuration lives.
|
||||
I use `homeConfigurations` to keep more than one configuration in the same repo (e.g., work (`j@lenny`) and personal computers (`j`, on any other system)).
|
||||
|
||||
To make it easier to install this configuration
|
||||
|
||||
### Running on NixOS
|
||||
|
||||
There are two ways to run it: as part of your general configuration (i.e., it will be applied using the same `nixos-rebuild` command) or standalone.
|
||||
I prefer the latter, because it allows me to tinker with the configuration more easily, and it is no different from applying it on other systems (see below).
|
||||
After you change your config, simply run:
|
||||
|
||||
```
|
||||
home-manager switch
|
||||
```
|
||||
|
||||
### On other systems
|
||||
|
||||
Running nix on other operating systems (e.g., Arch Linux) is similar to a standalone installation on NixOS.
|
||||
The only difference is that you need to [install nix first](https://nix.dev/install-nix.html) and [configure the appropriate channels](https://nix-community.github.io/home-manager/index.xhtml#sec-install-standalone).
|
||||
|
||||
|
||||
## It's a little flakey
|
||||
|
||||
Flakes are an experimental feature of nix that use version control and some special conventions to bring more reproducibility guarantees.
|
||||
For instance, they make it trivial to install a specific commit version of my home-manager config, which in itself could use program definitions from external git repositories.
|
||||
Flakes are not the only solution to this problem, and they are a bit controversial among hardcore nix users.
|
||||
However, the community as a whole seems to have embraced flakes.
|
||||
|
||||
I personally chose to set up my config as a flake.
|
||||
I still have not tried to install it on other systems, so time will tell.
|
||||
232
content/post/hyperloglog.md
Normal file
@@ -0,0 +1,232 @@
|
||||
---
|
||||
title: "HyperLogLog: magical (kind of) unique counters"
|
||||
description:
|
||||
date: 2025-09-08T20:08:22+02:00
|
||||
image:
|
||||
math:
|
||||
slug: hyperloglog
|
||||
license:
|
||||
hidden: false
|
||||
comments: true
|
||||
draft: false
|
||||
---
|
||||
|
||||
> **TL;DR**
|
||||
> [HyperLogLogs](https://en.wikipedia.org/wiki/HyperLogLog) (hll) can be a replacement for a set when only the number of unique elements (cardinality) is needed, **and an approximation is enough**.
|
||||
>
|
||||
> It is a very efficient structure both in time (`add` is `O(1)`) and space (fixed size typically ~12KB, depending on the desired error rate).
|
||||
>
|
||||
> Moreover, two hll can be **merged very efficiently ($O(1)$)**, with no loss of precision.
|
||||
|
||||
|
||||
## The problem
|
||||
|
||||
### A simplification
|
||||
|
||||
Imagine you are a store owner, and you want to count how many unique customers you get each day.
|
||||
Simple enough, you only need some pen and a piece of paper.
|
||||
Every time a customer walks in, you check whether their name is already on your paper[^1].
|
||||
If it is, you don't need to do anything.
|
||||
If it isn't, you add it.
|
||||
|
||||
[^1] You're a great store keeper, so you know every single customer by name!
|
||||
|
||||
At the end of the day, you simply count the number of names in your paper to get your answer.
|
||||
|
||||
One problem you may find is that checking whether a customer is already in the list can be slow, and you may not be able to keep up with the ludicrous thoroughput of customers to your successful store.
|
||||
There are some tricks to alleviate this:
|
||||
|
||||
* Sorting. Keeping your list of names always sorted. This can be very difficult with pen and paper :)
|
||||
* Partitioning. Separating your clients by some criteria (e.g., first letter in their surname) and assigning a portion of your paper for each possible value. You may repeat this process for each portion.
|
||||
* Deferring deduplication. Write their names every time, and wait until a later time to check if you have already seen them. That later time can be a less busy moment of the day, or some time after the day is over.
|
||||
|
||||
|
||||
The second problem is that the list of users
|
||||
|
||||
In a programming context, the first problem translate to time complexity.
|
||||
The typical approach is to have something like a a hash set.
|
||||
That makes checking very fast ($O(1)$).
|
||||
Adding a new name is also fast, unless the set needs to grow (amortized $O(1)$).
|
||||
A drawback is that hash sets need to be reasonably empty to work as intended, so we are trading speed for space.
|
||||
|
||||
The second problem translates to memory utilization.
|
||||
If each name has a length of $l$ bytes, and we have a total number of $u$ unique users, we would need **at least** $l \times u$ bytes, so $O(l \times u)$.
|
||||
For simplification, we can express $u$ as a product of how many times customers enter the store ($n$) and the ratio ($r$) of those visits that are from a unique customer: $u = n * r$.
|
||||
|
||||
### The real problem
|
||||
|
||||
You are such a great owner that your business has grown and you now have ten ($10$) more stores in town.
|
||||
Naturally, you want to see how each of the ten locations is doing, and you want to keep track of how unique customers your business has as a whole.
|
||||
So you need to:
|
||||
|
||||
- Keep a record of each individual store. In our case, that would mean $10$ times more total records.
|
||||
- Somehow merge the records from each location into one. If we have two counters, we need to go through all the elements of the smallest one, and add them to the bigger one. (plus optionally copying the biggest counter or starting anew and adding both to avoid modifying it)
|
||||
|
||||
This compounds the problems from the previous section:
|
||||
|
||||
- Each store does roughly the same, so the time and space needed grow $s$ times (for $s$ stores).
|
||||
- To merge the counters, we roughly need to go through each unique customer of each store.
|
||||
- We need to store the result. Depending on how many repetitions from store to store you get, this can go from as big as your biggest counter (all others are contained), up to the sum of all the counters (no repetition).
|
||||
|
||||
|
||||
So, in summary, assuming we can insert with $O(1)$ and we get on average $n$ customers per store, we need roughly:
|
||||
|
||||
- $O(s \times n)$ operations to get unique customers for every store.
|
||||
- $O(s \times n \times r)$ operations to join them.
|
||||
- $O((s+1) \times n \times r \times l)$ total space to save all of this information.
|
||||
|
||||
The two key factores here are that:
|
||||
|
||||
- Space grows linearly with the number of unique customers $n \times r$
|
||||
- Space grows lineraly with the number of stores ($s$)
|
||||
- Space grows linearly with the size of the key we are storing ($l$, length of names)
|
||||
- Merging time grows linearly with the number of stores ($s$)
|
||||
- Merging time grows linearly with the number of members in each counter ($n \times r$)
|
||||
|
||||
## Enter HyperLogLog
|
||||
|
||||
Let's look at a simpler problem before we explain the hyperlog.
|
||||
|
||||
Imagine you toss a coin until you get tails (or up to 100 throws).
|
||||
How likely are you to draw a sequence of at least 10 heads?
|
||||
For a fair coin, the probability of that event would be $1/2^{10}$
|
||||
And 5 heads?
|
||||
$1/2^5$.
|
||||
And, in general, $1/2^h$, for $h$ heads.
|
||||
|
||||
We can flip the problem on its head (pun intended).
|
||||
Let's say I repeat the same coin tossing multiple times, each time stopping when I get tails.
|
||||
If I tell you I got **at most** 10 heads and tell you to guess **how many tails I got** (i.e., total sequences), what would you say?
|
||||
|
||||
A naive answer would be that, in order to get an event with $1/2^10$ chance, I probably did about $2^10$ attempts.
|
||||
Much fewer or much more, and I would have gotten a different number.
|
||||
|
||||
> [!Warning]
|
||||
> This part is based on my (limited) understanding of the math behind HLL.
|
||||
> Please, take it with a grain of salt, and feel free to correct me.
|
||||
|
||||
The problem with this approach is that it produces very rough estimates (see the [Flajolet–Martin algorithm](https://en.wikipedia.org/wiki/Flajolet%E2%80%93Martin_algorithm), especially for higher values of $h$.
|
||||
|
||||
The key idea behind HyperLogLog is that, instead of keeping track of a single number, we separate our attempts into multiple groups (registers).
|
||||
Say, $m$ registers (for maxima).
|
||||
The first attempt affects the first register, the second the second one, and so on, until we run out of registers and we start again.
|
||||
Then, we get $m$ estimates of $n\_attempts / m$.
|
||||
It turns out using the harmonic mean of all the attempts and multiplying it by $m$ is a great estimate of the total number!
|
||||
|
||||
Could we use the same idea to solve our original problem?
|
||||
We only need a way to transform our input (the names) into a set of tosses.
|
||||
The output has to be deterministic (to work as a unique detector), uniform (assumption).
|
||||
|
||||
But that is precisely the definition of a hashing function!
|
||||
It turns an input into a series of ones and zeros of a fixed length.
|
||||
And the distribution of values of a good hashing function should be uniform in order to minimize collisions.
|
||||
|
||||
We can turn a hash into a sequence of tosses by keeping only the leading part up to the first 1.
|
||||
|
||||
Actually, another practical difference is that, instead of doing a round robin selection of registers, we will use part of the hash to select which register to update.
|
||||
The distribution of values should still be uniform, and we eliminate the need to keep a counter.
|
||||
So, we use just enough bits from the beginning to select the register ($log_2(m)$ for $m$ registers), and we convert the rest into a sequence.
|
||||
|
||||
It turns out that counting the number of leading zeros (most significant bit) is very fast on modern computers due to hardware support.
|
||||
And, no, that is not a coincidence.
|
||||
|
||||
In practical terms, we also need to apply some correction correct for hashing collisions.
|
||||
|
||||
Another practical difference is that there are hashing collisions. between and multiple hashes that start with the same sequence of zeros (and a one).
|
||||
|
||||
|
||||
That means that, a HLL has $m$ registers (maxima), and for each element that is added it:
|
||||
|
||||
- Calculates a hash of each element (to get a uniform distribution and a fixed size)
|
||||
- Assigns the element to one of the $R$ registers, $j$, based on the head of that hash (first $log_2(R)$ bits).
|
||||
- Counts $z$, the number of leading zeros in the tail of the hash
|
||||
- Increments the maximum in that register ($M[j] = max(z, M[j])$
|
||||
|
||||
To get an estimate of the cardinality we have three situations:
|
||||
|
||||
- The HLL does not have enough elements: $V > 0$, where $V$ is the number of zero elements. We use linear Counting ($E = m \times log( m / V))$)
|
||||
- The HLL has enough elements. We estimate the cardinality $E$ as: $E = m \times harmonic\_mean(M) \times c$. Where $c$ is a factor that corrects for hash collisions.
|
||||
- The HLL has too many elements. In this case, we need to correct the estimate from the second case.
|
||||
|
||||
The error of our estimation will be a function of the number of registers: $sigma = 1.04 / sqrt(m)$.
|
||||
|
||||
To merge two HLLs with the same number of registers and hashing functions, you only need to compare each register position, and get the maximum of the two values.
|
||||
This operation is very fast ($O(m)$, which is small in practice).
|
||||
There is also no loss of relative precision.
|
||||
|
||||
|
||||
Going back to our original problem, we will analyze the effect of using HLLs to estimate each the number of unique customers in each store.
|
||||
If we assume our hashing is $O(1)$ and we get on average $n$ customers per store, we get roughly:
|
||||
|
||||
- $O(s \times n)$ operations to get each store's unique customers
|
||||
- $O(s \times m)$ operations to join them. Where $m$ is the number of registers in each HLL.
|
||||
- $O((s+1) \times m)$ total space to save all of this information.
|
||||
|
||||
Hence, compared to our solution using sets:
|
||||
|
||||
- **Space ~grows linearly with~ does not depend on the number of unique customers**
|
||||
- Space grows lineraly with the number of stores ($m$)
|
||||
- **Space ~grows linearly with~ does not depend on the size of the key we are storing ($l$)**
|
||||
- Space depends linearly with the number of buckets, which is a function of the precision/error rate
|
||||
- Merging time grows linearly with the number of stores ($m$)
|
||||
- **Merging time ~grows linearly with~ does not depend on the number of members in each counter ($n$)**
|
||||
|
||||
|
||||
## Drawbacks
|
||||
|
||||
As magical as HLLs are, there are some caveats:
|
||||
|
||||
- The cardinality provided is an **estimation** up to an **error_rate**, usually in the rage of 1-2%
|
||||
- In order to merge two HLLs, they need to have:
|
||||
- The same number of registers
|
||||
- The same hash function
|
||||
- HyperLogLogs are append-only. You cannot remove elements
|
||||
- You cannot calculate the difference of two HLLs (but you can calculate its cardinality)
|
||||
|
||||
|
||||
## Additional properties
|
||||
|
||||
- The result of merging two HLLs has the same **error_rate**
|
||||
- It is possible to calculate the cardinality of:
|
||||
- the difference of two HLLs ($cardinality(a - b) = cardinality(a ∪ b) - cardinality(b)$)
|
||||
- the intersection of two HLLs ($cardinality(a ∩ b) = cardinality(a) + cardinality(b) - cardinality(a ∪ b)$)
|
||||
|
||||
## SlidingHyperLogLog
|
||||
|
||||
There are some really neat variations over HLLs for specific use cases.
|
||||
One I am specially interested in is the SlidingHyperLogLog, which can calculate the cardinality of events over a rolling window.
|
||||
An application of this would be to keep counters of unique IPs seen on a network over the past $W$ minutes.
|
||||
|
||||
Since HLL are only additive, it is not possible to apply the typical approach in sliding windows of removing old elements that are no longer within the window.
|
||||
The naive solution to get a Sliding Window counter of width $W$ ould be be to get all events that happened in the past $W$ minutes and construct a HLL with them.
|
||||
You would need to do that every $T$ minutes or for every incoming event, depending on your strategy/needs.
|
||||
That is unnecessarily wasteful.
|
||||
Imagine having a window of $W=120$ minutes with a resolution of $T=1$ minute.
|
||||
|
||||
Instead, the SlidingHyperLogLog exploits the fact that HLLs only keep track of the maximum count in each register.
|
||||
The intuition is that, when we add an element at time $t$ with count $V$ and belonging to register $r$, we can:
|
||||
|
||||
- Forget any elements in register $r$ that:
|
||||
- Were added before $t-W$
|
||||
- Had a count $<=V$
|
||||
- Add this event and time ($(t, V)$) to a list of values for the register
|
||||
- Update the count in the register to the maximum of all the remaining elements
|
||||
|
||||
Using some clever data structures (e.g., a binary heap) and algorithms, we can very efficiently perform the insertion and removal of events.
|
||||
|
||||
|
||||
## Python
|
||||
|
||||
For now, I've only used the [HyperLogLog](https://github.com/svpcom/hyperloglog/) library, which is a python implementation that relies on $numpy$:
|
||||
|
||||
```python
|
||||
!pip install hyperloglog
|
||||
|
||||
from hyperloglog import HyperLogLog
|
||||
|
||||
h = HyperLogLog(error_rate=0.01)
|
||||
|
||||
h.add("Hello from my blog")
|
||||
|
||||
print(len(h))
|
||||
```
|
||||
29
content/post/rdf-is-dead.md
Normal file
@@ -0,0 +1,29 @@
|
||||
---
|
||||
title: "RDF Is Dead"
|
||||
description:
|
||||
date: 2025-03-07T10:24:52+01:00
|
||||
image:
|
||||
math:
|
||||
tags:
|
||||
- semantic web
|
||||
license:
|
||||
hidden: false
|
||||
comments: true
|
||||
draft: false
|
||||
---
|
||||
|
||||
A big part of my research has been around vocabularies and semantic annotation.
|
||||
And, to be honest, I've grown increasingly dissatisfied with the field.
|
||||
To the point where I dread having to work on it.
|
||||
Some day I will write about it in length, but today I've stumbled upon a post that covers the topic quite well: [The Semantic Web is Dead - ~~Long Live the Semantic Web~~](https://terminusdb.com/blog/the-semantic-web-is-dead/) (styling mine).
|
||||
|
||||
In particular, this section has really resonated with me:
|
||||
|
||||
># Academics and Industry
|
||||
>
|
||||
>The political economy of academia and its interaction with industry is the origin of our current lack of a functional Semantic Web.
|
||||
>
|
||||
>Academia is structured in a way that there is very little incentive for anyone to build usable software. Instead, you are elevated for rapidly throwing together an idea, a tiny proof of concept, and to iterate on microscopic variations of this thing to produce as many papers as possible.
|
||||
>
|
||||
> In engineering, the devil is in the detail. You really need to get into the weeds before you can know what the right thing to do is. This is simultaneously a devastating situation for industry and academia. Nobody is going to wait around for a team of engineers to finish building a system to write about it in Academia. You’ll be passed immediately by legions of paper pushers. And in industry, you can’t just be mucking about with a system that you might have to throw away.
|
||||
{.note}
|
||||
21
content/post/rpi-hdmi-flickering.md
Normal file
@@ -0,0 +1,21 @@
|
||||
---
|
||||
title: Fixing HDMI flickering
|
||||
image: img/rpi.png
|
||||
readingTime: false
|
||||
categories:
|
||||
- Linux
|
||||
tags:
|
||||
- rpi
|
||||
- snippet
|
||||
---
|
||||
|
||||
Use this config to avoid HDMI flickering/intermittent blanking on RPI with a 1400x1050 VGA monitor.
|
||||
|
||||
```python
|
||||
|
||||
hdmi_drive=2
|
||||
hdmi_group=2
|
||||
hdmi_mode=42
|
||||
disable_overscan=1
|
||||
config_hdmi_boost=7
|
||||
```
|
||||
2
go.mod
@@ -2,4 +2,4 @@ module github.com/CaiJimmy/hugo-theme-stack-starter
|
||||
|
||||
go 1.17
|
||||
|
||||
require github.com/CaiJimmy/hugo-theme-stack/v3 v3.30.0 // indirect
|
||||
require github.com/CaiJimmy/hugo-theme-stack/v3 v3.31.0 // indirect
|
||||
|
||||
4
go.sum
@@ -1,2 +1,2 @@
|
||||
github.com/CaiJimmy/hugo-theme-stack/v3 v3.30.0 h1:uITC7EKGyfPjyi3C5At++E0Uu1qQXtqiwMV4pd7LkLs=
|
||||
github.com/CaiJimmy/hugo-theme-stack/v3 v3.30.0/go.mod h1:IPmCXiIxlFSLFYS0tOmYP6ySLviyeNVSabyvSuaxD+I=
|
||||
github.com/CaiJimmy/hugo-theme-stack/v3 v3.31.0 h1:fDdsTsOVVKBzQb9+hIxTErDqmiHCzcTD2Bd+7Se0TlA=
|
||||
github.com/CaiJimmy/hugo-theme-stack/v3 v3.31.0/go.mod h1:IPmCXiIxlFSLFYS0tOmYP6ySLviyeNVSabyvSuaxD+I=
|
||||
|
||||
{kind=link}
26
layouts/page/search.json
Normal file
@@ -0,0 +1,26 @@
|
||||
{{- $pages := where .Site.RegularPages "Type" "in" .Site.Params.mainSections -}}
|
||||
{{- $notHidden := where .Site.RegularPages "Params.hidden" "!=" true -}}
|
||||
{{- $filtered := ($pages | intersect $notHidden) -}}
|
||||
|
||||
{{- $result := slice -}}
|
||||
|
||||
{{- range $filtered -}}
|
||||
{{- $data := dict "title" .Title "date" .Date "permalink" .Permalink "content" (print .Plain "Tags: " (.Params.tags)) -}}
|
||||
|
||||
{{- $image := partialCached "helper/image" (dict "Context" . "Type" "articleList") .RelPermalink "articleList" -}}
|
||||
{{- if $image.exists -}}
|
||||
{{- $imagePermalink := "" -}}
|
||||
{{- if and $image.resource (default true .Page.Site.Params.imageProcessing.cover.enabled) -}}
|
||||
{{- $thumbnail := $image.resource.Fill "120x120" -}}
|
||||
{{- $imagePermalink = (absURL $thumbnail.Permalink) -}}
|
||||
{{- else -}}
|
||||
{{- $imagePermalink = $image.permalink -}}
|
||||
{{- end -}}
|
||||
|
||||
{{- $data = merge $data (dict "image" (absURL $imagePermalink)) -}}
|
||||
{{- end -}}
|
||||
|
||||
{{- $result = $result | append $data -}}
|
||||
{{- end -}}
|
||||
|
||||
{{ jsonify $result }}
|
||||
61
layouts/partials/article/components/details.html
Normal file
@@ -0,0 +1,61 @@
|
||||
<div class="article-details">
|
||||
{{ if .Params.categories }}
|
||||
<header class="article-category">
|
||||
{{ range (.GetTerms "categories") }}
|
||||
<a href="{{ .RelPermalink }}" {{ with .Params.style }}style="background-color: {{ .background }}; color: {{ .color }};"{{ end }}>
|
||||
{{ .LinkTitle }}
|
||||
</a>
|
||||
{{ end }}
|
||||
</header>
|
||||
{{ end }}
|
||||
|
||||
<div class="article-title-wrapper">
|
||||
<h2 class="article-title">
|
||||
<a href="{{ .RelPermalink }}">
|
||||
{{- .Title | markdownify -}}
|
||||
</a>
|
||||
</h2>
|
||||
|
||||
{{ with .Params.description }}
|
||||
<h3 class="article-subtitle">
|
||||
{{ . }}
|
||||
</h3>
|
||||
{{ end }}
|
||||
</div>
|
||||
|
||||
{{ $showReadingTime := .Params.readingTime | default (.Site.Params.article.readingTime) }}
|
||||
{{ $showDate := not .Date.IsZero }}
|
||||
{{ $showFooter := or $showDate $showReadingTime }}
|
||||
{{ if $showFooter }}
|
||||
<footer class="article-time">
|
||||
{{ if $showDate }}
|
||||
<div>
|
||||
{{ partial "helper/icon" "date" }}
|
||||
<time class="article-time--published">
|
||||
{{- .Date | time.Format (or .Site.Params.dateFormat.published "Jan 02, 2006") -}}
|
||||
</time>
|
||||
</div>
|
||||
{{ end }}
|
||||
|
||||
{{ if $showReadingTime }}
|
||||
<div>
|
||||
{{ partial "helper/icon" "clock" }}
|
||||
<time class="article-time--reading">
|
||||
{{ T "article.readingTime" .ReadingTime }}
|
||||
</time>
|
||||
</div>
|
||||
{{ end }}
|
||||
</footer>
|
||||
{{ end }}
|
||||
|
||||
{{ if .IsTranslated }}
|
||||
<footer class="article-translations">
|
||||
{{ partial "helper/icon" "language" }}
|
||||
<div>
|
||||
{{ range .Translations }}
|
||||
<a href="{{ .Permalink }}" class="link">{{ .Language.LanguageName }}</a>
|
||||
{{ end }}
|
||||
</div>
|
||||
</footer>
|
||||
{{ end }}
|
||||
</div>
|
||||
@@ -1 +0,0 @@
|
||||
{"Target":"/scss/style.min.663803bebe609202d5b39d848f2d7c2dc8b598a2d879efa079fa88893d29c49c.css","MediaType":"text/css","Data":{"Integrity":"sha256-ZjgDvr5gkgLVs52Ejy18Lci1mKLYee+gefqIiT0pxJw="}}
|
||||
{kind=link}
|
Before Width: | Height: | Size: 410 B |
{kind=link}
|
Before Width: | Height: | Size: 156 KiB |
{kind=link}
|
Before Width: | Height: | Size: 127 KiB |
{kind=link}
|
Before Width: | Height: | Size: 45 KiB |
{kind=link}
|
Before Width: | Height: | Size: 3.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 15 KiB |
{kind=link}
|
Before Width: | Height: | Size: 36 KiB |
{kind=link}
|
Before Width: | Height: | Size: 1.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 9.2 KiB |
{kind=link}
|
Before Width: | Height: | Size: 22 KiB |
{kind=link}
|
Before Width: | Height: | Size: 85 KiB |
{kind=link}
|
Before Width: | Height: | Size: 12 KiB |
{kind=link}
|
Before Width: | Height: | Size: 38 KiB |
{kind=link}
|
Before Width: | Height: | Size: 1.3 KiB |
{kind=link}
|
Before Width: | Height: | Size: 127 KiB |
{kind=link}
|
Before Width: | Height: | Size: 45 KiB |
{kind=link}
|
Before Width: | Height: | Size: 3.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 15 KiB |
{kind=link}
|
Before Width: | Height: | Size: 36 KiB |
{kind=link}
|
Before Width: | Height: | Size: 1.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 9.2 KiB |
{kind=link}
|
Before Width: | Height: | Size: 22 KiB |
{kind=link}
|
Before Width: | Height: | Size: 85 KiB |
{kind=link}
|
Before Width: | Height: | Size: 12 KiB |
{kind=link}
|
Before Width: | Height: | Size: 38 KiB |
{kind=link}
|
Before Width: | Height: | Size: 1.3 KiB |
BIN
static/img/emacs.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 46 KiB |
BIN
static/img/linux.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 78 KiB |
87
static/img/nixos.svg
Normal file
{kind=link}
@@ -0,0 +1,87 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<!-- Created with Inkscape (http://www.inkscape.org/) -->
|
||||
<svg xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:cc="http://creativecommons.org/ns#" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:svg="http://www.w3.org/2000/svg" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:sodipodi="http://sodipodi.sourceforge.net/DTD/sodipodi-0.dtd" xmlns:inkscape="http://www.inkscape.org/namespaces/inkscape" width="435.58978mm" height="136.68491mm" viewBox="0 0 1543.4284 484.31659" id="svg2" version="1.1" inkscape:version="0.92.0 r15299" sodipodi:docname="nixos-hex.svg">
|
||||
<defs id="defs4">
|
||||
<linearGradient inkscape:collect="always" id="linearGradient5562">
|
||||
<stop style="stop-color:#699ad7;stop-opacity:1" offset="0" id="stop5564"/>
|
||||
<stop id="stop5566" offset="0.24345198" style="stop-color:#7eb1dd;stop-opacity:1"/>
|
||||
<stop style="stop-color:#7ebae4;stop-opacity:1" offset="1" id="stop5568"/>
|
||||
</linearGradient>
|
||||
<linearGradient inkscape:collect="always" id="linearGradient5053">
|
||||
<stop style="stop-color:#415e9a;stop-opacity:1" offset="0" id="stop5055"/>
|
||||
<stop id="stop5057" offset="0.23168644" style="stop-color:#4a6baf;stop-opacity:1"/>
|
||||
<stop style="stop-color:#5277c3;stop-opacity:1" offset="1" id="stop5059"/>
|
||||
</linearGradient>
|
||||
<linearGradient id="linearGradient5960" inkscape:collect="always">
|
||||
<stop id="stop5962" offset="0" style="stop-color:#637ddf;stop-opacity:1"/>
|
||||
<stop style="stop-color:#649afa;stop-opacity:1" offset="0.23168644" id="stop5964"/>
|
||||
<stop id="stop5966" offset="1" style="stop-color:#719efa;stop-opacity:1"/>
|
||||
</linearGradient>
|
||||
<linearGradient y2="515.97058" x2="282.26105" y1="338.62445" x1="213.95642" gradientTransform="translate(983.36076,601.38885)" gradientUnits="userSpaceOnUse" id="linearGradient5855" xlink:href="#linearGradient5960" inkscape:collect="always"/>
|
||||
<linearGradient inkscape:collect="always" xlink:href="#linearGradient5562" id="linearGradient5384" gradientUnits="userSpaceOnUse" gradientTransform="translate(70.650339,-1055.1511)" x1="200.59668" y1="351.41116" x2="290.08701" y2="506.18814"/>
|
||||
<linearGradient inkscape:collect="always" xlink:href="#linearGradient5053" id="linearGradient5386" gradientUnits="userSpaceOnUse" gradientTransform="translate(864.69589,-1491.3405)" x1="-584.19934" y1="782.33563" x2="-496.29703" y2="937.71399"/>
|
||||
</defs>
|
||||
<sodipodi:namedview id="base" pagecolor="#ffffff" bordercolor="#666666" borderopacity="1.0" inkscape:pageopacity="0.0" inkscape:pageshadow="2" inkscape:zoom="0.34760742" inkscape:cx="803.54996" inkscape:cy="186.45699" inkscape:document-units="px" inkscape:current-layer="g5329" showgrid="false" inkscape:window-width="1366" inkscape:window-height="706" inkscape:window-x="0" inkscape:window-y="0" inkscape:window-maximized="1" inkscape:snap-global="true" fit-margin-top="0" fit-margin-left="0" fit-margin-right="0" fit-margin-bottom="0"/>
|
||||
<metadata id="metadata7">
|
||||
<rdf:RDF>
|
||||
<cc:Work rdf:about="">
|
||||
<dc:format>image/svg+xml</dc:format>
|
||||
<dc:type rdf:resource="http://purl.org/dc/dcmitype/StillImage"/>
|
||||
<dc:title/>
|
||||
</cc:Work>
|
||||
</rdf:RDF>
|
||||
</metadata>
|
||||
<g inkscape:groupmode="layer" id="layer7" inkscape:label="bg" style="display:none">
|
||||
<rect transform="translate(-132.5822,958.04022)" style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:1;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:#ffffff;fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;marker:none;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate" id="rect5389" width="1543.4283" height="483.7439" x="132.5822" y="-957.77832"/>
|
||||
</g>
|
||||
<g inkscape:groupmode="layer" id="layer5" inkscape:label="guide" style="display:none;opacity:0.51599995" transform="translate(-132.5822,958.04022)">
|
||||
<rect y="-957.77832" x="132.5822" height="483.7439" width="1543.4283" id="rect5350" style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:1;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:#d4d4d4;fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;marker:none;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate"/>
|
||||
<rect style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:1;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:#9b9b9b;fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;marker:none;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate" id="rect5346" width="1496.443" height="435.68069" x="155.77646" y="-933.38721" inkscape:export-xdpi="17.971878" inkscape:export-ydpi="17.971878"/>
|
||||
<rect y="-851.65918" x="159.02695" height="272.58423" width="1492.5731" id="rect5348" style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:1;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:#848484;fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;marker:none;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate"/>
|
||||
</g>
|
||||
<g inkscape:groupmode="layer" id="layer6" inkscape:label="logo-guide" style="display:none" transform="translate(-132.5822,958.04022)">
|
||||
<rect y="-958.02759" x="132.65129" height="484.30399" width="550.41602" id="rect5379" style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:1;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:#5c201e;fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;marker:none;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate" inkscape:export-filename="/home/tim/dev/nix/homepage/logo/nix-wiki.png" inkscape:export-xdpi="22.07" inkscape:export-ydpi="22.07"/>
|
||||
<rect style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:1;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:#c24a46;fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;marker:none;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate" id="rect5372" width="501.94415" height="434.30405" x="156.12303" y="-933.02759" inkscape:export-filename="/home/tim/dev/nix/homepage/logo/nixos-logo-only-hires-print.png" inkscape:export-xdpi="212.2" inkscape:export-ydpi="212.2"/>
|
||||
<rect style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:1;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:#d98d8a;fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;marker:none;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate" id="rect5381" width="24.939611" height="24.939611" x="658.02826" y="-958.04022"/>
|
||||
</g>
|
||||
<g inkscape:label="print-logo" inkscape:groupmode="layer" id="layer1" style="display:inline" sodipodi:insensitive="true" transform="translate(-132.5822,958.04022)">
|
||||
<path style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:1;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:#5277c3;fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate" d="m 309.40365,-710.2521 122.19683,211.6751 -56.15706,0.5268 -32.6236,-56.8692 -32.85645,56.5653 -27.90237,-0.011 -14.29086,-24.6896 46.81047,-80.4902 -33.22946,-57.8256 z" id="path4861" inkscape:connector-curvature="0" sodipodi:nodetypes="cccccccccc"/>
|
||||
<path style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:1;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:#7ebae4;fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate" d="m 353.50926,-797.4433 -122.21756,211.6631 -28.53477,-48.37 32.93839,-56.6875 -65.41521,-0.1719 -13.9414,-24.1698 14.23637,-24.721 93.11177,0.2939 33.46371,-57.6903 z" id="use4863" inkscape:connector-curvature="0" sodipodi:nodetypes="cccccccccc"/>
|
||||
<path style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:1;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:#7ebae4;fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate" d="m 362.88537,-628.243 244.41439,0.012 -27.62229,48.8968 -65.56199,-0.1817 32.55876,56.7371 -13.96098,24.1585 -28.52722,0.032 -46.3013,-80.7841 -66.69317,-0.1353 z" id="use4865" inkscape:connector-curvature="0" sodipodi:nodetypes="cccccccccc"/>
|
||||
<path style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:1;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:#7ebae4;fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate" d="m 505.14318,-720.9886 -122.19683,-211.6751 56.15706,-0.5268 32.6236,56.8692 32.85645,-56.5653 27.90237,0.011 14.29086,24.6896 -46.81047,80.4902 33.22946,57.8256 z" id="use4867" inkscape:connector-curvature="0" sodipodi:nodetypes="cccccccccc"/>
|
||||
<path sodipodi:nodetypes="cccccccccc" inkscape:connector-curvature="0" id="path4873" d="m 309.40365,-710.2521 122.19683,211.6751 -56.15706,0.5268 -32.6236,-56.8692 -32.85645,56.5653 -27.90237,-0.011 -14.29086,-24.6896 46.81047,-80.4902 -33.22946,-57.8256 z" style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:1;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:#5277c3;fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate"/>
|
||||
<path sodipodi:nodetypes="cccccccccc" inkscape:connector-curvature="0" id="use4875" d="m 451.3364,-803.53264 -244.4144,-0.012 27.62229,-48.89685 65.56199,0.18175 -32.55875,-56.73717 13.96097,-24.15851 28.52722,-0.0315 46.3013,80.78414 66.69317,0.13524 z" style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:1;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:#5277c3;fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate"/>
|
||||
<path sodipodi:nodetypes="cccccccccc" inkscape:connector-curvature="0" id="use4877" d="m 460.87178,-633.8425 122.21757,-211.66304 28.53477,48.37003 -32.93839,56.68751 65.4152,0.1718 13.9414,24.1698 -14.23636,24.7211 -93.11177,-0.294 -33.46371,57.6904 z" style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:1;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:#5277c3;fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate"/>
|
||||
<g id="layer2" inkscape:label="guides" style="display:none" transform="translate(72.039038,-1799.4476)">
|
||||
<path d="M 460.60629,594.72881 209.74183,594.7288 84.309616,377.4738 209.74185,160.21882 l 250.86446,1e-5 125.43222,217.255 z" inkscape:randomized="0" inkscape:rounded="0" inkscape:flatsided="true" sodipodi:arg2="1.5707963" sodipodi:arg1="1.0471976" sodipodi:r2="217.25499" sodipodi:r1="250.86446" sodipodi:cy="377.47382" sodipodi:cx="335.17407" sodipodi:sides="6" id="path6032" style="color:#000000;display:inline;overflow:visible;visibility:visible;opacity:0.23600003;fill:#4e4d52;fill-opacity:1;fill-rule:nonzero;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;marker:none;enable-background:accumulate" sodipodi:type="star"/>
|
||||
<path transform="translate(0,-308.26772)" sodipodi:type="star" style="color:#000000;display:inline;overflow:visible;visibility:visible;opacity:1;fill:#4e4d52;fill-opacity:1;fill-rule:nonzero;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;marker:none;enable-background:accumulate" id="path5875" sodipodi:sides="6" sodipodi:cx="335.17407" sodipodi:cy="685.74158" sodipodi:r1="100.83495" sodipodi:r2="87.32563" sodipodi:arg1="1.0471976" sodipodi:arg2="1.5707963" inkscape:flatsided="true" inkscape:rounded="0" inkscape:randomized="0" d="m 385.59154,773.06721 -100.83495,0 -50.41747,-87.32564 50.41748,-87.32563 100.83495,10e-6 50.41748,87.32563 z"/>
|
||||
<path transform="translate(0,-308.26772)" sodipodi:nodetypes="ccccccccc" inkscape:connector-curvature="0" id="path5851" d="m 1216.5591,938.53395 123.0545,228.14035 -42.6807,-1.2616 -43.4823,-79.7725 -39.6506,80.3267 -32.6875,-19.7984 53.4737,-100.2848 -37.1157,-73.88955 z" style="fill:url(#linearGradient5855);fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1"/>
|
||||
<rect style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:0.41499999;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:#c53a3a;fill-opacity:1;fill-rule:nonzero;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;marker:none;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate" id="rect5884" width="48.834862" height="226.22897" x="-34.74221" y="446.17056" transform="matrix(0.8660254,-0.5,0.5,0.8660254,0,0)"/>
|
||||
<path transform="translate(0,-308.26772)" sodipodi:type="star" style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:0.50899999;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;marker:none;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate" id="path3428" sodipodi:sides="6" sodipodi:cx="223.93674" sodipodi:cy="878.63831" sodipodi:r1="28.048939" sodipodi:r2="24.291094" sodipodi:arg1="0" sodipodi:arg2="0.52359878" inkscape:flatsided="true" inkscape:rounded="0" inkscape:randomized="0" d="m 251.98568,878.63831 -14.02447,24.29109 h -28.04894 l -14.02447,-24.29109 14.02447,-24.2911 h 28.04894 z"/>
|
||||
<use x="0" y="0" xlink:href="#rect5884" id="use4252" transform="matrix(0.5,0.8660254,-0.8660254,0.5,558.02636,12.372992)" width="100%" height="100%"/>
|
||||
<rect style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:1;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:#000000;fill-opacity:0.6507937;fill-rule:evenodd;stroke:none;stroke-width:1px;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;marker:none;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate" id="rect4254" width="5.3947482" height="115.12564" x="545.71014" y="467.07007" transform="matrix(0.8660254,0.5,-0.5,0.8660254,0,-308.26772)"/>
|
||||
</g>
|
||||
</g>
|
||||
<g inkscape:groupmode="layer" id="layer3" inkscape:label="gradient-logo" style="display:inline;opacity:1" sodipodi:insensitive="true" transform="translate(-132.5822,958.04022)">
|
||||
<path sodipodi:nodetypes="cccccccccc" inkscape:connector-curvature="0" id="path3336-6" d="m 309.54892,-710.38827 122.19683,211.67512 -56.15706,0.5268 -32.6236,-56.8692 -32.85645,56.5653 -27.90237,-0.011 -14.29086,-24.6896 46.81047,-80.4901 -33.22946,-57.8257 z" style="opacity:1;fill:url(#linearGradient5384);fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1"/>
|
||||
<use height="100%" width="100%" transform="rotate(60,407.11155,-715.78724)" id="use3439-6" inkscape:transform-center-y="151.59082" inkscape:transform-center-x="124.43045" xlink:href="#path3336-6" y="0" x="0"/>
|
||||
<use height="100%" width="100%" transform="rotate(-60,407.31177,-715.70016)" id="use3445-0" inkscape:transform-center-y="75.573958" inkscape:transform-center-x="-168.20651" xlink:href="#path3336-6" y="0" x="0"/>
|
||||
<use height="100%" width="100%" transform="rotate(180,407.41868,-715.7565)" id="use3449-5" inkscape:transform-center-y="-139.94592" inkscape:transform-center-x="59.669705" xlink:href="#path3336-6" y="0" x="0"/>
|
||||
<path style="color:#000000;clip-rule:nonzero;display:inline;overflow:visible;visibility:visible;opacity:1;isolation:auto;mix-blend-mode:normal;color-interpolation:sRGB;color-interpolation-filters:linearRGB;solid-color:#000000;solid-opacity:1;fill:url(#linearGradient5386);fill-opacity:1;fill-rule:evenodd;stroke:none;stroke-width:3;stroke-linecap:butt;stroke-linejoin:round;stroke-miterlimit:4;stroke-dasharray:none;stroke-dashoffset:0;stroke-opacity:1;color-rendering:auto;image-rendering:auto;shape-rendering:auto;text-rendering:auto;enable-background:accumulate" d="m 309.54892,-710.38827 122.19683,211.67512 -56.15706,0.5268 -32.6236,-56.8692 -32.85645,56.5653 -27.90237,-0.011 -14.29086,-24.6896 46.81047,-80.4901 -33.22946,-57.8256 z" id="path4260-0" inkscape:connector-curvature="0" sodipodi:nodetypes="cccccccccc"/>
|
||||
<use height="100%" width="100%" transform="rotate(120,407.33916,-716.08356)" id="use4354-5" xlink:href="#path4260-0" y="0" x="0" style="display:inline"/>
|
||||
<use height="100%" width="100%" transform="rotate(-120,407.28823,-715.86995)" id="use4362-2" xlink:href="#path4260-0" y="0" x="0" style="display:inline"/>
|
||||
</g>
|
||||
<g style="display:inline" inkscape:label="text-vegur" id="g5329" inkscape:groupmode="layer" transform="translate(-132.5822,958.04022)">
|
||||
<g aria-label="Nix" style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-size:395.09683228px;line-height:125%;font-family:Carlito;-inkscape-font-specification:Carlito;letter-spacing:0px;word-spacing:0px;display:inline;opacity:1;fill:#000000;fill-opacity:1;stroke:none;stroke-width:1px;stroke-linecap:butt;stroke-linejoin:miter;stroke-opacity:1" id="text5407">
|
||||
<path d="m 969.15319,-847.11833 h -30.81755 v 139.86428 c 0,19.75484 0.79019,50.96749 1.97548,85.73601 h -1.18529 c -15.40877,-28.84207 -32.79303,-56.49884 -45.04104,-75.46349 l -96.79872,-150.1368 h -42.27536 v 267.87565 h 30.81755 v -139.86427 c 0,-19.75485 -0.79019,-56.89395 -1.97548,-91.26737 h 1.18529 c 22.91561,39.90478 36.34891,62.0302 48.99201,80.99485 l 96.79872,150.13679 h 38.32439 z" style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-family:Vegur;-inkscape-font-specification:Vegur" id="path4683"/>
|
||||
<path d="m 1027.8251,-579.24268 h 33.1881 v -191.22686 h -33.1881 z m 16.594,-219.27874 c 11.4578,0 20.5451,-9.08722 20.5451,-20.54503 0,-11.45781 -9.0873,-20.54504 -20.5451,-20.54504 -11.4578,0 -20.545,9.08723 -20.545,20.54504 0,11.45781 9.0872,20.54503 20.545,20.54503 z" style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-family:Vegur;-inkscape-font-specification:Vegur" id="path4685"/>
|
||||
<path d="m 1267.7785,-770.46954 h -37.9293 l -46.6214,70.32723 h -1.1853 l -45.0411,-70.32723 h -41.09 l 68.3517,93.24285 v 1.18529 l -70.7223,96.79872 h 37.9293 l 49.7822,-75.85859 h 1.1853 l 49.7822,75.85859 h 41.09 l -72.3027,-98.37911 v -1.18529 z" style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-family:Vegur;-inkscape-font-specification:Vegur" id="path4687"/>
|
||||
</g>
|
||||
<g aria-label="O" transform="scale(0.95067318,1.0518862)" style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-size:367.48727417px;line-height:125%;font-family:Carlito;-inkscape-font-specification:Carlito;letter-spacing:0px;word-spacing:0px;display:inline;opacity:1;fill:#000000;fill-opacity:1;stroke:none;stroke-width:1px;stroke-linecap:butt;stroke-linejoin:miter;stroke-opacity:1" id="text5356">
|
||||
<path d="m 1468.5915,-800.79725 c -66.1477,0 -120.5358,48.14083 -120.5358,128.25306 0,80.11223 54.3881,128.25306 120.5358,128.25306 66.1477,0 120.5359,-48.14083 120.5359,-128.25306 0,-80.11223 -54.3882,-128.25306 -120.5359,-128.25306 z m 0,24.98914 c 49.2433,0 86.727,36.74872 86.727,103.26392 0,66.5152 -37.4837,103.26392 -86.727,103.26392 -49.2433,0 -86.727,-36.74872 -86.727,-103.26392 0,-66.5152 37.4837,-103.26392 86.727,-103.26392 z" style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-family:Vegur;-inkscape-font-specification:Vegur" id="path4680"/>
|
||||
</g>
|
||||
<g aria-label="S" style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-size:386.55480957px;line-height:125%;font-family:Carlito;-inkscape-font-specification:Carlito;letter-spacing:0px;word-spacing:0px;display:inline;opacity:1;fill:#000000;fill-opacity:1;stroke:none;stroke-width:1px;stroke-linecap:butt;stroke-linejoin:miter;stroke-opacity:1" id="text5364">
|
||||
<path d="m 1523.761,-773.88643 c 0,37.10927 19.3277,57.21012 64.1681,75.37819 34.4034,13.91598 48.3193,26.28573 48.3193,51.79835 0,30.92438 -25.126,46.38657 -58.3697,46.38657 -17.395,0 -37.1093,-2.70588 -58.7564,-10.05042 l -3.479,26.67228 c 18.9412,6.95799 39.8152,9.66387 60.6891,9.66387 51.7984,0 95.0925,-26.28573 95.0925,-79.24374 0,-36.7227 -22.4202,-54.50422 -67.6471,-72.6723 -30.1512,-11.9832 -44.8403,-24.73951 -44.8403,-51.41179 0,-25.89917 22.4202,-40.2017 50.6387,-40.2017 16.6218,0 34.7899,4.2521 47.5462,9.27732 l 3.479,-26.28573 c -14.6891,-6.18488 -32.8572,-9.27732 -52.958,-9.27732 -47.5463,0 -83.8824,27.4454 -83.8824,69.96642 z" style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-family:Vegur;-inkscape-font-specification:Vegur" id="path4677"/>
|
||||
</g>
|
||||
</g>
|
||||
</svg>
|
||||
|
After Width: | Height: | Size: 25 KiB |
BIN
static/img/python.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 52 KiB |
BIN
static/img/rpi.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 7.1 KiB |
BIN
static/img/uv.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 59 KiB |